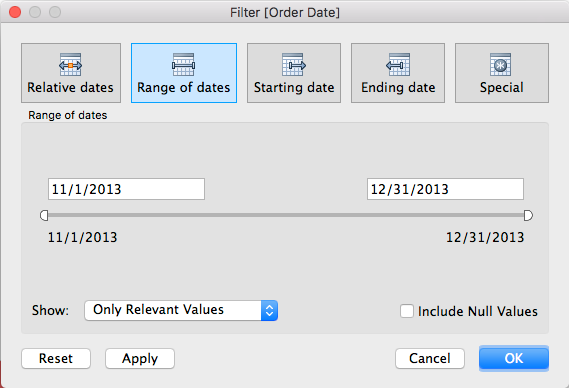
As you start working with Power BI, you’ll encounter an important decision: How do I connect to data in my reports, and what is the difference between Import vs Direct Query Power BI? Then you google for insights and find a few “technical consultant” focused blogs, that discuss significant differences thing sentences, and we wanted to make a comprehensive article for more audience members.
Your chosen connection method will depend on the source database and your analytics needs. Once connected, you can visualize and analyze the data in your reports using Power BI’s interactive dashboard. That’s where “Import” and “Direct Query” come into play. But what does Import vs Direct Query Power BI mean?
Both allow you to uncover hidden opportunities using data. Data governance for PowerBI is essential for operationalizing how data is refreshed in analytics projects. This ensures that the dashboard meets the organization’s analytics needs and takes advantage of the benefits of data governance. This means you’re not guessing between the directory method (aka live) or Import (aka extract) between each report because it’s an established offering for analytics projects. It’s advantageous for your analytics needs. Teams often set a few data freshness and time analytics options and then apply those limitations to all incoming reports. This ensures the data access credentials are up-to-date, providing a snapshot of the most recent information.
Introduction to Connecting to Data in Powerbi
You may also encounter this situation when you realize that the DirectQuery feature doesn’t work with your underlying data source or that the Import feature doesn’t update fast enough. You may wonder if you need to rebuild your data models.
The decision to use analytics extends beyond databases and includes various data sources such as online services, spreadsheets, APIs, and more.
In Power BI, users can choose the direct query method for their analytics needs. This choice becomes noticeable as they set up data connections and build their dashboards in Power BI.
You are choosing between Import Vs. Direct Query in Power BI, at first, is easy to skip without considering its long-term impact or the implications it may have as your prototype dashboard goes from DEV to PROD. When working with Direct Query to utilize data sets effectively, it is essential to understand the data connectivity and the underlying data source.
The first time you see the comparison between “Import Vs. Direct Query”
The first time, in Power BI, is while connecting to data.
Suppose you’re using a relational database like Microsoft SQL Server. In that case, you can import data into Power BI using Import Mode or connect directly to the database using Direct Query Mode for analytics.
As we researched, we found many technical blogs written to help people explain the tech technical aspects and insights using Power BI Service and Power BI Desktop. Still, we didn’t find direct content that explained it in a way we could easily share with business, sales, marketing teams, or executives using Power BI service and Power BI desktop. Ideally, this comprehensive guide will help explain to technical and non-technical users, as both should know about the process from multiple perspectives because it presents the overall availability of the data with both ups and downsides.
Consider Import and Direct Query as two different roads or paths leading to the same destination.
Insights in the Power BI service. Each road or path, including direct query, has advantages and considerations; we’ll help you navigate them. Whether you’re just starting your Power BI journey or looking to make more informed choices about data connections, this direct query may become your friendly companion.
Import Mode in Power BI is like bringing all your data into Power BI using DirectQuery. It’s fast, flexible, and lets you create powerful visualizations. With a direct query, you can work on your data even when offline, just like playing with building blocks.
On the other hand, Direct Query Mode is more like having a direct line to your data source with direct query. DirectQuery is a real-time feature in Power BI that doesn’t store your data inside the platform. It’s as if you’re looking at a live feed.
Selecting between Import or Direct Query involves critical decisions, like choosing between different game modes.
What is Import Data Mode?
The Import Data Mode in Power BI is like bringing all your data into Power BI’s playground using DirectQuery. Here’s a closer look:
The most common method used in Power BI is the DirectQuery Import Data Mode. In this direct query mode, you directly pull data from various sources—such as databases, spreadsheets, online services, and more—into Power BI.
This is extract in Tableau Desktop.
Power BI’s internal engine copies and stores the data using a direct query. Think of it as filling your toy box with all your favorite toys, including direct queries, making them readily available whenever you want to play.
This approach offers several key benefits:
Benefits of Import Data Mode
Speed: Since the data is stored within Power BI’s direct query functionality, it can be processed and analyzed quickly. With DirectQuery, your reports and visualizations using DirectQuery respond almost instantly, providing a smooth user experience.
Offline Access: With DirectQuery, you can work on your reports in Import Mode without an internet connection. It’s like having direct toys wherever you go without accessing the original data source.
Data Transformation and Modeling: In Import Mode, direct query gives you complete control over your data. To build a coherent and insightful dataset, you can shape, clean, and create relationships between tables with direct queries. This natural flexibility is like being the master of your toy kingdom, arranging everything just how you want.
How to Import Data in Power BI
Importing data into Power BI is straightforward:
Data Source Selection: First, you choose the direct data source you want to import from. This could be an SQL database, an Excel spreadsheet, a cloud service like Azure or Google Analytics, or many others that support direct queries.
Data Transformation: You can perform data transformations using Power Query, a powerful tool built into Power BI. This step allows you to clean, reshape, and prepare your data for analysis.
Data Modeling: In this phase, you create relationships between tables, define measures, and design your data model. It’s like assembling your toys in a way that they interact and tell a meaningful story.
Loading Data: Finally, you load the transformed and modeled data into Power BI. This data is ready to build reports, dashboards, and visualizations.
Data Transformation and Modeling
Data transformation and modeling are critical steps in Import Mode:
Data Transformation: Power Query allows you to perform various transformations on your data. You can filter out unnecessary information, merge data from multiple sources, handle missing values, and more. This is like customizing your toys to fit perfectly in your playtime scenario.
Data Modeling: In Power BI’s Data View, you define relationships between tables. These relationships enable you to create meaningful visuals. It’s similar to connecting different parts of your toys to create an exciting and cohesive storyline.
Performance Considerations
While Import Mode offers many advantages, it’s essential to consider performance factors:
Data Refresh: As your data evolves, you must regularly refresh it to keep your reports current. The frequency and duration of data refresh can impact the overall performance of your Power BI solution.
Data Volume: Large datasets can consume a significant amount of memory. Monitoring and optimizing your data model is essential to ensure it doesn’t become unwieldy.
Data Source Connectivity: The performance of data import depends on the speed and reliability of your data source. Slow data sources can lead to delays in report generation.
Data Compression: Power BI uses compression techniques to reduce the size of imported data. Understanding how this compression works can help you manage performance effectively.
What is Direct Query Mode?
Direct Query Mode in Power BI is like allowing an executive to see data when it’s in the database. They are running a query on that database when they start the report. This is great for dashboards that only have a few users or if the database is optimized for traffic, you can increase the traffic. However, as a rule of thumb, it’s best to keep direct queries for those who need to access data immediately and try to use Import for everything else.
This usual question of “when was this refreshed?” will have the exciting answer of “when you opened the report.”
This is called “Live” in Tableau Desktop.
In Direct Query Mode, you establish a direct connection from Power BI to your data source, such as a database, an online service, or other data repositories. Instead of importing and storing the data within Power BI, it remains where it is. Imagine it as if you’re watching your favorite TV show as it’s being broadcast without recording it. This means you’re always viewing the most up-to-date information, which can be crucial for scenarios where real-time data is essential.
Benefits of Direct Query Mode
Real-time or Near-real-time Data: Direct Query provides access to the latest data in your source system. This is invaluable when monitoring rapidly changing information, such as stock prices, customer interactions, or sensor data.
Data Source Consistency: Data isn’t duplicated in Power BI; maintain consistency with the source system. Any changes in the source data are reflected in your reports, eliminating the risk of using outdated information.
Resource Efficiency: Direct Query Mode doesn’t consume as much memory as Import Mode since it doesn’t store data internally. This can be advantageous when dealing with large datasets or resource-constrained environments.
Supported Data Sources
Power BI’s Direct Query Mode supports a variety of data sources, including:
Relational Databases: This includes popular databases like Microsoft SQL Server, Oracle, MySQL, and PostgreSQL, among others.
Online Services: You can connect to cloud-based services like Azure SQL Database, Google BigQuery, and Amazon Redshift.
On-premises Data: Direct Query can also access data stored on your organization’s servers, provided a network connection.
Custom Data Connectors: Power BI offers custom connectors that allow you to connect to various data sources, even those not natively supported.
Creating a Direct Query Connection
Setting up a Direct Query connection involves a few steps:
Data Source Configuration: Start by defining the connection details to your data source, such as server address, credentials, and database information.
Query Building: Once connected, you can create queries using Power BI’s query editor to specify which data you want to retrieve. Think of this as choosing the TV channel you want to watch.
Modeling and Visualization: As with Import Mode, you’ll need to design your data model and create visualizations in Power BI, but with Direct Query, the data stays in its original location.
Performance Considerations
While Direct Query offers real-time data access, there are some performance considerations to keep in mind:
Data Source Performance: The speed of your Direct Query connection depends on the performance of your data source. (Your dashboard calculations and complexity are equally crucial for performance, but this is the distance between data source and the dashboards). Slow or poorly optimized databases can delay retrieving data, but that’s dashboard-level performance and not data source performance. Both are significant, and both are different.
Query Optimization: Efficiently written queries can significantly improve performance. Power BI’s query editor provides tools to help you optimize your queries.
Data Volume: Large datasets may still impact performance, especially when complex calculations are involved. Efficient data modeling is essential to mitigate this.
Data Source Compatibility: Not all data sources are compatible with Direct Query. Ensure your data source supports this mode before attempting to create a connection.
Direct Query Mode is a powerful tool when you need real-time access to your data, but understanding its benefits, limitations, and how to optimize its performance is crucial for a successful implementation in your Power BI projects.
When to Use Import vs. Direct Query
Regarding Power BI, how you access and interact with your data is not one-size-fits-all. It depends on your specific needs and the nature of your data. In this section, we’ll explore the scenarios that favor two fundamental data access modes: Import Mode and Direct Query Mode. Additionally, we’ll delve into the concept of Hybrid Models, where you can blend the strengths of both modes to create a tailored solution that best fits your data analysis requirements. Whether you seek real-time insights, optimized performance, or a careful balance between data freshness and resource efficiency, this section will guide you toward making the right choice for your unique scenarios.
Scenarios Favoring Import Mode
Data Exploration and Transformation:Import Mode shines when you clean, shape, and transform your data before creating reports. It allows you to consolidate data from multiple sources, perform calculations, and create a unified data model within Power BI. This is especially valuable when dealing with disparate data sources that require harmonization.
Offline Accessibility: Importing data into Power BI provides the advantage of working offline. Once you’ve imported the data, you can create, modify, and view reports without needing a live connection to the source. This is crucial for situations where consistent access to data is required, even when the internet connection is unreliable or unavailable.
Complex Calculations: Import Mode allows you to perform complex calculations, aggregations, and modeling within Power BI. This is advantageous when you need to create advanced KPIs, custom measures, or calculated columns that rely on data from various sources.
Performance Optimization: You can optimize performance by importing data into Power BI. Since the data resides within Power BI’s internal engine, queries and visualizations respond quickly, providing a smooth user experience, even with large datasets.
Data Security and Compliance: Import Mode is often favored when data security and compliance are paramount. By controlling access to the imported data, you can protect sensitive information, making it suitable for industries with strict regulatory requirements.
Scenarios Favoring Direct Query Mode
Real-time Data Analysis: Direct Query Mode is essential when you require up-to-the-minute data insights. It’s perfect for monitoring stock prices, tracking website traffic, or analyzing real-time sensor data. With Direct Query, you see changes as they happen.
Large and Evolving Datasets: When working with massive datasets that are frequently updated, importing all the data can be impractical or resource-intensive. Direct Query ensures you always work with the most current information without worrying about data refresh schedules or storage limitations.
Data Source Consistency: In situations where maintaining data source consistency is critical, such as financial reporting or compliance monitoring, Direct Query ensures that your reports reflect the exact state of the source data, avoiding any discrepancies or data staleness.
Resource Efficiency: Direct Query is resource-efficient since it doesn’t store data internally. This makes it suitable for scenarios where memory or storage constraints are a concern, especially in large enterprises or organizations with limited IT resources.
Hybrid Models: Combining Import and Direct Query
In some cases, the best approach involves combining both Import and Direct Query modes in what is known as a “Hybrid Model.” Here’s when and why you might choose this approach:
A blend of Historical and Real-time Data: Hybrid models are beneficial when you need a combination of historical data (imported for analysis) and real-time data (accessed through Direct Query). For example, you might import historical sales data while using Direct Query to monitor real-time sales.
Data Volume Management: You can use Import Mode for the most critical or frequently accessed data and Direct Query for less frequently accessed or rapidly changing data. This way, you strike a balance between performance and data freshness.
Combining Data Sources: Sometimes, you may need to combine data from sources best suited for different modes. For example, you might import financial data from a spreadsheet (Import Mode) and connect to an external API for real-time market data (Direct Query).
Optimizing Performance: By strategically choosing where to use Import and Direct Query, you can optimize the overall performance of your Power BI solution. For instance, you can alleviate resource constraints by using Direct Query for the most resource-intensive data sources while leveraging Import Mode for the rest.
Hybrid models provide flexibility and allow you to tailor your Power BI solution to meet your organization’s specific needs, combining the strengths of both Import and Direct Query modes to maximize efficiency and data freshness.
A Comprehensive Overview of Data Refreshes when choosing between Important VS Direct Query.
To navigate this landscape effectively, one must understand the nuances of data access modes. In this section of the “Power BI Comprehensive Guide,” we delve into two pivotal aspects: “Scheduled Refresh in Import Mode” and “Real-time Data in Direct Query Mode.” These elements are the gears that keep your data engine running smoothly, offering distinct advantages for different scenarios.
Scheduled Refresh in Import Mode automates keeping your data up-to-date, ensuring your reports and dashboards reflect the latest information. We’ll explore its benefits, such as automated data updates and historical analysis while considering factors like data source availability and performance impact.
Real-time Data in Direct Query Mode opens a window into the world of instantaneous insights. Discover how this mode allows you to access data as it happens, perfect for scenarios like stock market analysis, web analytics, and IoT data monitoring. However, we’ll also delve into the critical considerations, such as data source performance and query optimization.
Lastly, we’ll examine the critical topic of Data Source Limitations, where not all data sources are created equal. Understanding the compatibility and capabilities of your data sources, especially in the context of Direct Query Mode, is vital for a successful Power BI implementation.
As we navigate these aspects, you’ll gain a deeper understanding of the mechanics that drive data access in Power BI, empowering you to make informed decisions about which mode suits your unique data analysis needs. So, let’s dive into the world of data access modes and uncover the tools you need for data-driven success.
Scheduled Refresh in Import Mode
Scheduled Refresh is critical to working with Import Mode in Power BI. This feature lets you keep your reports and dashboards up-to-date with the latest data from your source systems. Here’s a more detailed explanation:
Scheduled Refresh allows you to define a refresh frequency for your imported data. For example, you can set it to refresh daily, hourly, or even more frequently, depending on the requirements of your reports and the frequency of data updates in your source systems. Power BI will re-query the data sources during each scheduled refresh, retrieve the latest information, and update your datasets.
Scheduled Refresh is beneficial in several scenarios:
Automated Data Updates: It automates the data retrieval and refresh process, reducing manual efforts. This is particularly useful for large datasets or multiple data sources.
Timely Insights: Scheduled Refresh ensures that your reports and dashboards always reflect the most current data available. This is essential for data-driven decision-making.
Historical Analysis: It allows you to maintain a historical record of your data, enabling you to analyze trends, track changes over time, and make informed historical comparisons.
However, it’s essential to consider some key factors when setting up Scheduled Refresh:
Data Source Availability: Your data sources must be accessible and available during the scheduled refresh times. If the data source becomes unavailable, the refresh process may fail.
Performance Impact: Frequently scheduled refreshes can strain your data source, so balancing data freshness and performance is essential.
Data Volume: The size of your dataset and the complexity of data transformations can affect the duration of the refresh process. Optimizing your data model and query performance is crucial.
Real-time Data in Direct Query Mode
In Direct Query Mode, real-time data access is one of its defining features. Here’s a more detailed explanation:
Direct Query Mode lets you connect to data sources in real-time or near-real time. This means that when new data is added or updated in the source system, it becomes immediately available for analysis in your Power BI reports. It’s like having a live feed of your data, and it’s precious in scenarios where timeliness is critical.
Some use cases for real-time data in Direct Query Mode include:
Stock Market Analysis: Traders and investors rely on up-to-the-second stock price data to make informed decisions.
Web Analytics: Businesses need real-time insights into website traffic, click-through rates, and user behavior to optimize their online presence.
IoT Data Monitoring: Industries like manufacturing and healthcare depend on real-time data from IoT sensors to ensure smooth operations and patient safety.
Real-time data in Direct Query Mode comes with considerations
Data Source Performance: The performance of your data source becomes crucial, as any delays or downtimes in the source system will directly impact the real-time data feed.
Query Optimization: Queries in Direct Query Mode should be optimized to minimize latency and ensure fast response times.
Data Source Limitations
While Power BI supports a wide range of data sources, it’s essential to be aware of potential limitations, especially in Direct Query Mode. Here’s an overview:
Data Source Compatibility: Not all data sources are compatible with Direct Query Mode. Some sources might not support real-time access or have limited capabilities when used in this mode. It’s essential to check the documentation and compatibility of your data source with Power BI.
Complex Transformations: In Direct Query Mode, some complex data transformations possible in Import Mode may not be supported. This can impact your ability to create calculated columns or measures directly within Power BI.
Performance Considerations: Direct Query Mode’s performance depends heavily on your data source’s performance. Slow or resource-intensive queries on the source side can lead to slower response times in Power BI.
Understanding the limitations and capabilities of your data sources is crucial for making informed decisions when choosing between Import Mode and Direct Query Mode in your Power BI projects.
Performance Considerations Using Import vs Direct Query Power BI
Factors Affecting Import Mode Performance
In import mode, performance considerations are essential for efficient data analysis. The primary factor influencing import mode performance is the size and complexity of your dataset. When dealing with larger datasets, loading data into the local or in-memory cache can become resource-intensive and time-consuming. As the dataset grows, memory usage increases, potentially leading to performance bottlenecks. Additionally, the complexity of data transformations and calculations within the data model can slow down import mode. To mitigate this, data model optimization becomes crucial, ensuring that the model is streamlined and calculations are as efficient as possible. Another factor affecting performance is the hardware resources available. Adequate RAM and CPU power are necessary to support large datasets and complex calculations. Lastly, the frequency of data refreshes should be carefully considered. Frequent refreshes can strain system resources and impact the user experience, so finding the right balance between data freshness and performance is essential.
Factors Affecting Direct Query Mode Performance
Direct Query mode, on the other hand, introduces a different set of performance considerations. This mode connects to the data source in real time, eliminating the need to load data into a local cache. However, the speed and reliability of the data source connection become critical factors. A slow or unreliable connection can lead to delays in query execution, impacting the user experience. Additionally, the complexity of queries plays a significant role in Direct Query mode. Complex queries involving multiple data sources or intricate calculations can result in slower
performance. It’s imperative to optimize your queries to ensure they run efficiently. Furthermore, the performance of Direct Query mode relies heavily on optimizing the data source itself. Proper indexing and tuning of the data source are essential for fast query execution. Lastly, managing concurrency is vital in this mode, as multiple users accessing the same data source concurrently can lead to performance challenges. Therefore, implementing effective concurrency management is necessary to maintain a smooth user experience.
Optimization Tips for Import vs Direct Query Power BI
Several optimization strategies can be employed to enhance the performance of both import and Direct Query modes. First and foremost, data cleansing should be a priority. Cleaning and preprocessing the data before importing or connecting in Direct Query mode can significantly reduce unnecessary data, improving performance. Data compression techniques should also be utilized to reduce data size and optimize memory usage, especially in import mode. Implementing appropriate indexing strategies is crucial in both modes. In Direct Query mode, this ensures that tables in the data source are well-indexed for faster query execution, while in import mode, it helps with data retrieval efficiency. Aggregations can be employed in import mode to precompute summarized data, substantially boosting query performance. Partitioning large datasets is another valuable technique for import mode, as it helps distribute the load and improves data refresh times. Regular performance monitoring is essential to identify and address bottlenecks, ensuring data analysis and reporting remain efficient over time.
Security and Data Sensitivity when Using Import vs Direct Query Power BI
Data Security in Import Mode
Regarding data security in import mode, protecting the data stored in the local cache is paramount. Access control measures should be implemented to restrict data access based on user roles and permissions. This ensures that only authorized individuals can view and interact with sensitive data. Encryption is another critical aspect of data security at rest and in transit. Encrypting the data protects it from unauthorized access or interception during transmission. Furthermore, maintaining audit logs is essential for tracking data access and changes made to the data model. This auditing capability enhances security and aids in compliance and accountability efforts.
Data Security in Direct Query Mode
In Direct Query mode, data security focuses on securing data at the source. Secure authentication methods should be implemented to ensure that only authorized users can access the data source. Proper authorization mechanisms must be in place to control access at the source level, ensuring that users can only retrieve the data they are entitled to view. Additionally, data masking techniques can be employed to restrict the exposure of sensitive information in query results. By implementing data masking, you protect sensitive data from being inadvertently exposed to unauthorized users, maintaining high data security and privacy. Overall, in both import and Direct Query modes, a robust data security strategy is vital to safeguard sensitive information and maintain the trust of users and stakeholders.
Compliance and Privacy Considerations: Import vs Direct Query Power BI
Compliance and privacy considerations are paramount in data analysis and reporting using import or Direct Query modes. Ensuring compliance with regulations such as GDPR and HIPAA is a top priority. This involves controlling data access, implementing encryption measures, and defining data retention policies that align with legal requirements. Data residency is another critical aspect to consider. Determining where your data is stored and transmitted is essential to ensure compliance with regional data residency regulations and restrictions. Data anonymization or pseudonymization should also be part of your compliance strategy to protect individual privacy while still allowing for meaningful analysis. Furthermore, consent management mechanisms should be in place, enabling users to provide explicit consent for data processing and sharing. These considerations collectively form a robust compliance and privacy framework that ensures your data analysis practices adhere to legal and ethical standards.
Data Modeling and Transformation
Data modeling in import mode involves structuring your data to optimize the efficiency of data analysis. One of the critical principles often applied in this mode is the use of a star schema. Data is organized into fact tables and dimension tables in a star schema. Fact tables contain the core business metrics and are surrounded by dimension tables that provide context and attributes related to those metrics. This schema design simplifies query performance, allowing for more straightforward navigation and data aggregation.
Calculated columns play a crucial role in import mode data modeling. By creating calculated columns for frequently used calculations, you can improve query speed. These calculated columns can encompass various calculations, such as aggregations, custom calculations, or even derived dimensions, which simplify and expedite generating insights from your data. Furthermore, defining relationships between tables is essential in import mode to ensure data can be accurately and efficiently navigated. Properly defined relationships enable users to create meaningful reports and visualizations.
Data Modeling in Direct Query Mode
In Direct Query mode, data modeling focuses on optimizing query performance rather than designing data structures in the local cache. Crafting efficient SQL queries is paramount in this mode. Ensuring your queries are well-structured and utilizing database-specific optimizations can significantly impact query response times. Query optimization techniques, such as query folding, are valuable for pushing data transformations back to the data source, reducing the amount of data transferred and processed by the reporting tool.
Additionally, proper indexing of tables in the data source is critical. A well-indexed data source can dramatically improve query execution speed. Indexes enable the database to quickly locate the necessary data, reducing the time it takes to retrieve and process results. Data modeling in Direct Query mode is closely tied to the performance optimization of the underlying data source. Ensuring the data source is well-tuned for query performance is essential for delivering fast and responsive reports.
Differences and Limitations Visualization and Reporting
Building Reports in Import Mode
Building reports in import mode offers several advantages, primarily regarding the complexity and richness of visualizations and dashboards that can be created. Since data is stored locally in a cache, it is readily available for immediate manipulation and visualization. This means you can make interactive and visually appealing reports with various visual elements, including charts, graphs, and complex calculated fields. However, there are limitations to consider. Reports in import mode may suffer from slower refresh times, especially when dealing with large datasets. Additionally, real-time data updates often require scheduled refreshes, resulting in data lag between updates and the availability of new information in reports.
Building Reports in Direct Query Mode
Building reports in Direct Query mode offers real-time data access without the need for data duplication. This model is well-suited for scenarios where up-to-the-minute data is critical. However, the level of complexity in visualizations may be limited compared to import mode. Due to the need for real-time querying and potential performance constraints, some complex visualizations may not be feasible. High-concurrency scenarios can also impact query responsiveness, as multiple users accessing the same data source concurrently may experience delays in query execution.
Deployment and Sharing
Publishing Reports in Import Mode
Publishing reports in import mode is relatively straightforward, as the reports are self-contained with data stored in the local cache. These reports can be published on various platforms and accessed by users without directly connecting to the original data source. Users can interact with these reports offline, which can be advantageous when internet connectivity is limited. However, managing data refresh schedules effectively is essential to ensure that the data in the reports remains up-to-date.
Publishing Reports in Direct Query Mode
Publishing reports in Direct Query mode requires a different approach. These reports are connected to live data sources, and as such, they require access to the data source to provide interactivity. Users must have access to the data source to interact with the reports effectively. This mode’s dependency on data source availability and performance should be considered when publishing reports. Ensuring the data source is maintained correctly and optimized to support the reporting workload is essential.
Sharing Options and Limitations
Sharing options differ between import and Direct Query modes due to their distinct characteristics. Import mode reports are more portable, containing the data within the report file. Users can share these reports independently of the data source, simplifying distribution. In contrast, Direct Query reports have more stringent requirements since they rely on a live connection to the data source. This means that sharing Direct Query reports may involve granting access to the data source or hosting the reports on a platform that provides the necessary data connectivity. These considerations should be factored into your sharing and distribution strategy.
Best Practices: Import vs. Direct Query Power BI
Like most SaaS products that are packed full of optimal or suboptimal decisions that will meet expectations during testing time, and we recommend you begin testing as soon as possible to ensure your system can handle Direct Query or the Import Mode, which has a limit of 8 total schedule windows unless you decide to utilize the PowerBI REST API, we will save that for another blog, and know it’s a good step for batch style refreshes that can be accessed via standard programming languages or data engineering services.
Best Practices for Import Mode
To optimize performance in import mode, several best practices should be followed. First, data models should be optimized for speed and efficiency. This includes using star schemas, calculated columns, and well-defined relationships between tables. Data compression and aggregation techniques should be employed to reduce data size and enhance memory usage. Scheduled data refreshes should be during off-peak hours to minimize user disruption. Monitoring and managing memory usage is essential to prevent performance degradation over time, as large datasets can consume substantial system resources.
Best Practices for Direct Query Mode
In Direct Query mode, query optimization is critical. Craft efficient SQL queries that fully utilize the database’s capabilities and optimizations. Ensure that tables in the data source are appropriately indexed to facilitate fast query execution. Monitoring data source performance is crucial, as it directly impacts the responsiveness of Direct Query reports. Educating users on query performance considerations and best practices can also help mitigate potential issues and ensure a smooth user experience.
Common Pitfalls to Avoid
Common pitfalls must be avoided in Import and Direct Query modes to ensure a successful data analysis and reporting process. Overloading import mode with massive datasets can lead to performance issues, so it’s essential to balance the size of the dataset with available system resources. In Direct Query mode, neglecting to optimize data source indexes can result in slow query performance, harming the user experience. Implementing proper data security and compliance measures in both modes can expose sensitive data and lead to legal and ethical issues. Finally, neglecting performance monitoring and optimization in either mode can result in degraded performance and user dissatisfaction.
Use Cases and Examples
Industry-specific Examples
Data analysis and reporting are critical in decision-making and operations in various industries. For instance, in the retail industry, businesses use data analysis to track sales performance, optimize inventory management, and make data-driven pricing decisions. Data analysis helps monitor patient outcomes, assess treatment efficacy, and improve healthcare delivery. The finance sector relies on data analysis for tracking financial transactions, detecting fraud, and making investment decisions. Each industry has unique challenges and opportunities where data analysis can drive improvements and efficiencies.
Real-world Use Cases
Real-world use cases for data analysis and reporting are diverse and encompass many applications. Sales analytics is an everyday use case involving analyzing sales data by region, product, and time to identify trends and opportunities. Customer engagement analysis helps businesses measure customer satisfaction, engagement, and loyalty, providing insights to enhance the customer experience. Operational efficiency analysis identifies bottlenecks, streamlines processes, and optimizes organization resource allocation. These use cases illustrate how data analysis and reporting can be applied across various domains to improve decision-making and drive positive outcomes.
Conclusion
In conclusion, choosing between import mode and Direct Query mode depends on your specific data analysis and reporting needs and your data environment’s capabilities: performance, security, and compliance considerations.
Here is an excellent place to start inviting others to the conversation and ensure others understand what is happening without extra engineering. Like executives getting LIVE reports versus EXTRACTS, maybe this is where we talk about STREAMING?
All modes offer unique advantages and limitations, and a well-informed decision should align with your organization’s goals and requirements. Staying updated on emerging trends and developments in data analysis tools is essential to adapt to evolving needs and technologies. Practical data analysis and reporting are critical for informed decision-making and success in today’s data-driven world.
The ability to network with data science professionals is a valuable skill that can open doors to exciting opportunities and foster your personal and professional growth. It would be best if you created long-lasting connections while networking. Long-lasting relationships that will get you ahead in life, and similar to attending school, these are people who you can depend on for your entire lifetime.
Whether you are an Excel guru, analyst, engineer, intern, office admin, executive, or just someone interested in data science, building a solid network of data professionals can provide insights, mentorship, collaboration opportunities, and potential job prospects.
This article will guide you through the essential steps to effectively network with data professionals.
The more you practice, the more you can recall these successful attempts and your confidence will grow.
Being a technical person, it’s easy to rabbit-hole unnecessarily about strange topics related to what you love! Learning social cues before you start messaging people or meeting new people is good. Every new person will help you learn. Document everything in a spreadsheet and create a dashboard to share your success over some time.
How Can I Tell If I’m Being Annoying?
It can be challenging to understand whether or not you’re coming across as being annoying, and we think it’s best to be yourself, honest, and truthful. However, what if being yourself isn’t working? Perhaps we can pick up some new strategies before we begin. Often, looking back on previous convos can be an excellent way to realize what strategies are working and what’s not working. This is why many organizations are moving to NLP solutions built into their phone call systems; this allows them to hear what is working and what is not working with immediate feedback.
It’s essential to be aware of social cues to determine if you might be annoying someone during a conversation. Here are some signs that may indicate the other person is getting annoyed:
Body Language: Watch for signs of discomfort in their body language. These may be signs of irritation or discomfort if they fidget, cross their arms, or avoid eye contact.
Short Responses: If the person begins responding with quick, curt answers or seems disinterested in continuing the conversation, it’s a sign that they may not be enjoying the interaction.
Repetitive Topics: If you keep bringing up the same topic or steering the conversation back to yourself, the other person may find it annoying. It’s crucial to balance talking about yourself with showing genuine interest in their thoughts and experiences.
Overwhelming Questions: If you’re bombarding the person with too many questions or questions that are too personal, they may feel overwhelmed or uncomfortable.
Lack of Engagement: If the other person stops asking you questions or stops actively participating in the conversation, it could be a sign that they’re not enjoying the interaction.
Interrupting: Constantly interrupting or not allowing others to speak can be annoying. It’s important to let them express themselves and actively listen.
Unwanted Advice: Offering unsolicited advice or opinions on sensitive topics can be irritating. It’s generally best to offer advice or opinions when asked.
Negative Tone: If you sense a change in the person’s tone, such as becoming more curt or sarcastic, it may indicate annoyance.
Physical Distancing: If the person physically moves away from you during the conversation, it’s a clear sign that they may be uncomfortable.
Excessive Texting or Distraction: If the person starts checking their phone frequently or appears distracted, it could indicate that they are no longer engaged in the conversation.
It’s essential to be sensitive to these cues and adjust your behavior accordingly.
While working in customer service jobs before college, I spoke to hundreds of people per day, and had an opportunity to see what’s working for me and what’s not. Then while working at Tableau Software, I attended many sales conferences, and used my years of customer service experience and applied it to my interpersonal communication skills.
by tyler garrett, founder of dev3lop
Interpersonal communication is an exchange of information between two or more people. It is also an area of research that seeks to understand how humans use verbal and nonverbal cues to accomplish a number of personal and relational goals.
from wiki
If you suspect you may be annoying someone, it’s a good idea to politely ask if everything is okay or if they’re still interested in the conversation.
Here are ten ideas you can ask someone during the convo to check to see if you’re being annoying. I enjoy #1. Hopefully, these spark ideas on how to communicate comfortably with others.
“I hope I’m not talking too much about myself. How’s the conversation been for you?”
“Is there anything you’d like to discuss or any more interesting topic?”
“Am I being too intense or enthusiastic about this topic?”
“Are there any specific things I’ve said or done that bother you?”
“Is there anything I can do to make our conversation more enjoyable?”
“I’ve noticed I’ve been asking a lot of questions. Is there anything else you’d like to share or discuss?”
“Is there a specific way you prefer to have conversations I should be aware of?”
“Do you have any feedback or suggestions on how I can improve our interaction?”
“Is there a topic or subject you’re passionate about that we can discuss instead?”
“I want to ensure you’re comfortable in our conversation. If there’s anything I should change, please let me know.”
Respect their response and be prepared to exit the conversation if needed gracefully. Remember that not everyone will find the same annoying, so it’s also essential to be yourself and know the other person’s comfort level.
Managing Toxic Users in Online Communities
Dealing with Toxic Online Communities and Users: 6 Strategies for Safeguarding Your Well-Being
While meeting data science gurus, you’ll quickly learn not every community is the same and not all data gurus are the same. Encountering toxic behavior or a toxic online community/user can be distressing, and it’s inevitable. Here are six strategies to help you navigate and protect your well-being in such situations:
Limit Interaction: The first and most effective step is to limit your interaction with toxic individuals or communities. Avoid engaging in arguments or responding to negative comments. If possible, mute, block, or unfollow toxic users to minimize exposure to their content.
Seek Support: Reach out to friends, family, or trusted online friends for emotional support. Discussing your experiences with those you trust can provide a sense of validation and help you process your feelings about the situation.
Report and Document: If the toxicity crosses a line into harassment or abuse, use the platform’s reporting mechanisms to alert moderators or administrators. Document any offensive or harmful content, which can help build a case if needed.
Maintain Boundaries: Set clear boundaries for what you’re willing to tolerate. Don’t be afraid to assert yourself and express your discomfort when necessary. Remember that it’s okay to disengage from any community or individual who consistently exhibits toxic behavior.
Importance of Blocking: Blocking toxic individuals is crucial in protecting your online well-being. Blocking prevents further interaction and provides peace of mind, allowing you to curate a safer and more positive online environment.
Self-Care: Prioritize self-care. Engage in activities that bring you joy, relaxation, and peace. This may include stepping away from online interactions, pursuing hobbies, or practicing mindfulness. Taking care of your mental and emotional well-being is essential in the face of toxicity.
Dealing with toxicity online can be challenging, but employing these strategies, including the importance of blocking, can help you safeguard your well-being and maintain a positive online experience.
Attend Conferences and Meetups
Now that you’re ready to leave the nest check out a local meetup. It’s time to leave the toxic people behind!
Let’s think hard: where can we meet tech people? You can hear about new companies, companies hiring, people pitching their new products, and even sitting at a local coffee shop.
However, once you’re all done with coffee, you could head to data science conferences and meetups, as they are the cornerstone of building a robust network within the data professional community. Often, it’s one big party from sun up until sun down; most of the time, everyone is having a great time, and it’s always an easy way to meet someone with an interest equal to yours.
Here’s an in-depth exploration of why these events are so effective for networking:
1. Networking Opportunities: Data science conferences and meetups attract professionals from various backgrounds and expertise levels. This diversity provides an ideal setting for expanding your network. Whether you’re a seasoned data scientist or just starting out, you’ll have the chance to connect with like-minded individuals who share your passion for data.
2. Knowledge Sharing: These events are hubs of knowledge sharing. Not only do you get to attend presentations and workshops led by experts, but you can also engage in discussions with fellow attendees. The exchange of ideas, experiences, and insights can be precious, enhancing your understanding of the field.
3. Exposure to the Latest Trends: Data science is rapidly evolving. Conferences and meetups often feature talks on cutting-edge technologies, methodologies, and tools. By staying informed about the latest trends and developments, you can position yourself as an informed and forward-thinking professional, which can be attractive to potential collaborators or employers.
4. Access to Experts: These events frequently bring in prominent figures in the data science world as speakers. Meeting and interacting with these experts can be invaluable for your career. You can gain insights, seek advice, and even establish mentor-mentee relationships with individuals who have succeeded.
5. Potential Mentorship: Conferences and meetups are excellent places to find mentors or advisors who can guide your data science journey. Many experienced professionals are open to offering guidance, sharing their experiences, and helping newcomers navigate the intricacies of the field.
6. Serendipitous Encounters: Sometimes, the most fruitful connections happen by chance. You might meet someone who shares a common interest, has complementary skills, or works on a project that aligns with your goals. These serendipitous encounters can lead to productive collaborations, research projects, or job opportunities.
7. Building Your Reputation: Active participation in conferences and meetups can help you establish your reputation in the data science community. You can showcase your expertise and gain recognition as a knowledgeable and engaged professional by asking insightful questions during sessions, giving presentations, or contributing to panel discussions.
8. Friendships and Support: Beyond professional benefits, attending conferences and meetups can lead to personal connections and friendships. Having a network of supportive peers can be instrumental in overcoming challenges and celebrating successes.
In conclusion, attending data science conferences and meetups is more than just a way to acquire knowledge. It’s a strategic approach to building a network of professionals who can offer guidance, collaboration, mentorship, and even potential job opportunities. By actively participating in these events and seizing networking opportunities, you can enrich your career and make lasting connections in the data science world.
Utilize LinkedIn
LinkedIn is a large website where you can host your resume and have headhunters reach out to you about jobs. There’s more to it but if you’re networking, you’re also probably on the market to get a job. Having a LinkedIn is a best practice.
Why use LinkedIn? LinkedIn is a powerful tool for networking with data professionals.
Once you’ve created a well-structured LinkedIn profile highlighting your skills, achievements, and interests in the data field. You can begin to join data science groups and engage in discussions, connect with professionals, and reach out for informational interviews or collaborations.
You’re now a content creator; you need to regularly share relevant content and insights to establish your credibility within the data community. It’s not mandatory, but it’s a great way to meet others and tell the algorithm you’re essential, giving you more visibility on your posts.
Utilize LinkedIn for Effective Networking with Data Professionals
LinkedIn has emerged as an indispensable tool for networking and career development in today’s digital age. When it comes to the data science field, here’s how you can harness the power of LinkedIn for networking with data professionals:
1. Optimize Your Profile: Your LinkedIn profile is your digital identity in the professional world. To make the most of it, ensure your profile is complete, accurate, and engaging. Highlight your skills, education, and relevant experience. Use a professional photo and write a compelling summary that encapsulates your passion for data and career goals.
2. Join Data Science Groups: LinkedIn offers various groups and communities tailored to diverse professional interests. Look for data science groups, such as “Data Science Central,” “Data Science and Machine Learning,” or specific groups related to your niche within data science. Joining these groups is an excellent way to connect with like-minded individuals who share your interests and are actively involved in the field.
3. Engage in Discussions: Once you’re a member of these groups, actively engage in discussions. Share your insights, ask questions, and participate in conversations related to data science topics. By contributing meaningfully to these discussions, you demonstrate your knowledge and passion for the field, and you’ll start to gain visibility among your peers.
4. Connect with Professionals: Leverage LinkedIn’s networking capabilities by connecting with data professionals whose work or interests align with yours. When sending connection requests, personalize your messages, indicating your desire to connect and potentially collaborate or learn from each other. A personalized message is more likely to be well-received than a generic one.
5. Informational Interviews: LinkedIn is a valuable platform for contacting data professionals for informational interviews. If you’re interested in a specific career path or seeking advice, don’t hesitate to request a brief conversation. Many professionals are open to sharing their insights and experiences, making informational interviews a potent networking tool.
6. Showcase Your Knowledge: Establish your credibility within the data community by regularly sharing relevant content, such as articles, research papers, or your own insights on data science trends. Sharing valuable content keeps you engaged with your network and positions you as an informed and influential professional.
7. Personal Branding: Use LinkedIn to build your brand in data science. This involves consistently sharing your experiences, achievements, and the projects you’ve worked on. When others see your accomplishments, they’re more likely to respect and connect with you as a professional.
8. Recommendations and Endorsements: Ask for recommendations and endorsements from colleagues, mentors, or supervisors who can vouch for your skills and expertise. These endorsements add credibility to your profile and make you more attractive to potential employers or collaborators.
9. Stay Updated: LinkedIn is a dynamic platform, and the more active you are, the more likely you are to stay on the radar of your connections. Regularly update your profile with new skills, experiences, and accomplishments. Share industry news and engage with your connections’ content to stay in the loop with the latest developments in data science.
In summary, LinkedIn is a powerful networking tool for data professionals. By creating a strong and engaging profile, actively participating in data science groups, connecting with professionals, sharing insights, and using the platform to seek advice or collaborations, you can expand your network, enhance your credibility, and open doors to a wealth of opportunities within the data science community.
Online Forums and Communities
Participating in online data science forums and communities like Stack Overflow, Kaggle, or Reddit’s r/datascience can help you connect with professionals and enthusiasts. Each community has its ups and downs; consider them an ocean of possibility and take everything with a grain of salt.
Ensure you actively contribute to discussions, seek advice, and offer assistance to others.
These communities often provide a supportive environment for learning and networking.
Leveraging Online Forums and Communities for Networking in Data Science
In the digital age, online forums and communities have become invaluable hubs for knowledge sharing, networking, and collaboration within the data science field. Here’s how you can make the most of these online platforms:
1. Active Participation: Engaging with online data science communities requires active participation. Whether you choose platforms like Stack Overflow, Kaggle, or Reddit’s r/datascience, actively contribute to discussions, respond to questions, and join conversations on topics that interest you. Participating regularly demonstrates your passion for the field and makes yourself more visible to others in the community.
2. Seek Advice and Share Knowledge: Online forums provide an excellent platform to seek advice when facing challenges or uncertainties in your work or studies. Don’t hesitate to ask questions; you’ll often find experienced professionals willing to provide guidance. Conversely, offer assistance and share your knowledge if you have expertise in a particular area. This reciprocal exchange of information is a powerful networking tool.
3. Showcase Your Skills: These platforms allow you to showcase your skills and expertise. You establish yourself as a knowledgeable and helpful professional when you help others by providing thoughtful and insightful responses. This can lead to others reaching out to connect or collaborate with you.
4. Collaboration Opportunities: Online communities are teeming with individuals working on data-related projects. By actively participating in these communities, you increase the likelihood of finding potential collaborators. Whether you’re looking for partners on a research project, a coding challenge, or a data competition, these platforms are fertile ground for forming connections with like-minded professionals.
5. Learning and Skill Development: Online forums are not just about networking but also about continuous learning. You’ll gain valuable insights and learn new skills by participating in discussions and seeking answers to your questions. This helps you advance in your data science journey and gives you more to bring to the table when networking with others.
6. Building Your Reputation: A strong presence in online data science communities can help you build your reputation in the field. You become a respected figure in the community when you consistently provide high-quality responses, engage in thoughtful discussions, and showcase your skills. Others will likely contact you for collaborations, advice, or job opportunities.
7. Supportive Environment: Many data science forums and communities have a culture of support and encouragement. The sense of camaraderie and shared passion for data science creates a welcoming environment for networking. You’ll often find individuals who are eager to help and share their experiences.
8. Networking Beyond Borders: Online communities are not bound by geographical constraints. You can connect with data professionals worldwide, gaining a diverse perspective and expanding your network far beyond your local area.
9. Staying Informed: Many online platforms feature discussions on the latest trends, tools, and technologies in the data science field. Staying active in these communities keeps you updated about industry developments and enables you to discuss emerging trends.
In conclusion, participating in online data science forums and communities is an effective way to connect with professionals and enthusiasts, learn, share your expertise, and find collaboration opportunities. The supportive environment of these platforms makes them ideal for networking, and active involvement can help you build a strong network while enhancing your knowledge and skills in the field.
Collaborate on Projects
Collaborative projects are an excellent way to network with data professionals. Join data-related projects on platforms like GitHub or Kaggle and contribute your skills and expertise. Working together on real-world projects builds your experience and allows you to connect with people who share similar interests.
Harnessing the Power of Collaborative Projects for Networking in Data Science
Collaboration on data-related projects is a dynamic and practical approach to network with data professionals while simultaneously honing your skills and gaining hands-on experience. Here’s an in-depth look at the benefits and strategies of collaborating on data projects:
1. Real-World Experience: Collaborative projects allow you to apply your data science skills to real-world problems. By actively participating in these projects, you gain practical experience and enhance your problem-solving abilities. This hands-on experience is highly regarded by employers and collaborators alike.
2. Skill Development: Working on collaborative projects exposes you to diverse challenges, data sets, and problem domains. This exposure helps you expand your skill set, allowing you to become a more versatile and knowledgeable data professional.
3. Networking with Peers: Collaborative platforms such as GitHub, Kaggle, and GitLab often attract a community of data enthusiasts and professionals. By contributing to open-source projects or joining data challenges, you connect with like-minded individuals who share your passion for data science. These peers can become valuable connections for future collaborations or career opportunities.
4. Exposure to Diverse Perspectives: Collaborative projects often involve individuals from various backgrounds, each offering a unique perspective and set of skills. This diversity can lead to innovative solutions and foster creative thinking. Engaging with people from different professional and cultural backgrounds broadens your horizons and enriches your problem-solving capabilities.
5. Building a Portfolio: The projects you collaborate on are a testament to your skills and expertise. A portfolio showcasing your contributions to meaningful data projects can be a powerful tool for attracting potential collaborators, mentors, and employers.
6. Open Source Contributions: Open-source projects are a great way to give back to the data science community while expanding your network. Many data professionals appreciate contributions to open-source tools and libraries, which can lead to recognition and new opportunities within the community.
7. Interdisciplinary Collaboration: Data science often intersects with various fields, from healthcare to finance to climate science. Collaborative projects offer a chance to work with professionals from other domains. This interdisciplinary experience can provide unique networking opportunities and broaden your understanding of how data science applies across industries.
8. Problem Solving and Critical Thinking: Collaborative projects involve tackling complex data problems. By participating in these projects, you not only enhance your technical skills but also develop your problem-solving and critical-thinking abilities. These qualities are highly valued in the data science community and can set you apart.
9. Enhanced Communication Skills: Collaborating with others on data projects requires effective communication. You’ll need to articulate your ideas, share your progress, and clearly explain your work. These experiences can improve your communication skills, which are crucial for networking and collaboration.
10. Showcasing Your Value: When you actively contribute to a collaborative project, you demonstrate your dedication and value as a team player. This can lead to more meaningful connections with peers and mentors who appreciate your commitment to the project’s success.
In conclusion, collaborative projects are not just a means of building experience and enhancing your skills but also an exceptional way to network with data professionals who share your interests and passions. Through hands-on collaboration, you can build a strong network, expand your horizons, and open the door to exciting opportunities within the data science community.
Attend Webinars and Online Courses
In the age of digital learning, webinars, and online courses offer an excellent opportunity to network with data professionals from the comfort of your home. Sign up for webinars, workshops, and courses hosted by experts in the field. Engage in Q&A sessions and discussion forums to connect with presenters and fellow participants.
The Power of Webinars and Online Courses for Networking in Data Science
In our digital era, webinars and online courses have revolutionized learning and networking. They provide an incredible opportunity to connect with data professionals, learn from experts, and expand your network. Here’s a detailed exploration of how you can effectively network through webinars and online courses:
1. Convenience and Accessibility: Webinars and online courses allow you to access valuable content and network with professionals without geographical limitations. You can participate from the comfort of your home or office, making it a flexible and accessible way to engage with the data science community.
2. Expert-Led Learning: Many webinars and online courses are led by industry experts and thought leaders in the data science field. Attending these events expands your knowledge and gives you access to influential professionals who are often open to networking and engagement.
3. Engage in Q&A Sessions: Most webinars and online courses include interactive Q&A sessions. This is an excellent opportunity to ask questions, seek clarification, and interact with presenters. Engaging in these sessions allows you to stand out and be remembered by the experts leading the event.
4. Discussion Forums: Many online courses offer discussion forums where participants can interact, share insights, and discuss the course content. These forums are platforms for learning and great places to connect with like-minded individuals. Actively participating in discussions can lead to networking opportunities.
5. Build a Learning Network: As you attend webinars and online courses, you’ll naturally connect with fellow participants who share your interests and goals. These connections form the basis of your “learning network,” a group of individuals with whom you can exchange knowledge, insights, and experiences.
6. Gain Exposure to New Ideas: Webinars and online courses often introduce you to new ideas, trends, and technologies in the data science field. By staying informed and discussing these emerging topics, you position yourself as someone passionate about staying up-to-date, which can be attractive to potential collaborators or employers.
7. Networking Beyond Borders: Online courses often have a global reach, allowing you to network with data professionals worldwide. This diversity can provide unique perspectives and create networking opportunities beyond your local network.
8. Connecting with Instructors: Instructors of online courses are typically experienced professionals or academics in the field. Engaging with them can lead to valuable networking opportunities. You can ask for advice, share your experiences, and potentially establish a mentorship or collaboration with them.
9. Expand Your Skillset: Online courses are designed to provide in-depth knowledge and skill development. As you gain expertise in specific areas of data science, you become a more attractive collaborator and network contact for those looking for individuals with specialized skills.
10. Share Insights: When participating in webinars and online courses, you can share your own insights and experiences. This positions you as a valuable contributor to the community, and others may reach out to connect with you based on your contributions.
In conclusion, webinars and online courses offer a convenient and effective way to network with data professionals. By actively engaging in Q&A sessions, discussion forums, and other interactive components, you can connect with experts, build your learning network, and stay on the cutting edge of data science while expanding your connections within the field.
Seek Mentorship
When I was on the Tableau Consulting team at Tableau (before Salesforce acquisition), I was lucky to be mentored by many different people from around the world, and that’s why I think it’s important to begin seeking mentorship as soon as possible. Be sure to diversify your mentorship and always be on the look out for your next mentor.
Mentorship can be a valuable asset in your professional journey. Reach out to experienced data professionals you admire and respect, and express your interest in learning from them. A mentor can provide guidance, insights, and a network of their own that can greatly benefit your career.
The Value of Mentorship in Data Science: A Guiding Light for Your Career
Mentorship is a time-honored practice with immense potential for anyone looking to grow and excel in their professional journey, particularly in data science. Here’s a detailed exploration of how mentorship can be a powerful asset for your career:
1. Learning from Experience: One of the primary advantages of seeking a mentor in data science is the opportunity to learn from someone who has walked the path before you. An experienced mentor can provide valuable insights, share lessons from their journey, and guide you away from common pitfalls and challenges.
2. Tailored Guidance: A mentor can offer personalized guidance that addresses your unique career goals and challenges. By understanding your specific needs and aspirations, a mentor can provide targeted advice and recommendations, making your career development more effective and efficient.
3. Access to a Network: Mentors typically have extensive networks in the industry. You gain access to their professional contacts and connections by developing a mentor-mentee relationship. This expanded network can open doors to collaboration, job opportunities, and introductions to other influential figures in data science.
4. Accountability and Motivation: A mentor can be an accountability partner, helping you set and achieve your career goals. Regular check-ins with your mentor can keep you motivated and on track, ensuring that you progress in your career.
5. Insight into Best Practices: Your mentor can provide valuable insights into best practices in data science. They can help you understand the tools, techniques, and approaches that are most relevant and effective in the field, saving you time and effort in staying up-to-date.
6. Soft Skills Development: Data science is not just about technical skills; soft skills such as communication, problem-solving, and project management are equally crucial. A mentor can help you develop and refine these skills, making you a more well-rounded professional.
7. Feedback and Constructive Criticism: Mentors can provide feedback and constructive criticism, helping you identify areas where you can improve and grow. This feedback is often candid and based on their extensive experience, making it a valuable resource for personal development.
8. Encouragement and Confidence: A mentor can be a source of encouragement and confidence-building. They can provide reassurance during challenging times, helping you navigate setbacks and maintain a positive attitude as you progress in your career.
9. Personal Growth: Mentorship often extends beyond your professional life, positively impacting your personal development. The wisdom and guidance shared by your mentor can influence your decision-making, problem-solving abilities, and even your values and principles.
10. Legacy and Giving Back: Many experienced data professionals find fulfillment in giving back to the community by mentoring others. By being open to mentorship, you not only gain from their knowledge but also contribute to the passing down of knowledge and expertise within the data science field.
11. Networking Opportunities: You can also gain access to their professional circle through your mentor. This can result in introductions and networking opportunities that might not have been possible without their guidance.
In conclusion, mentorship is a powerful asset in your professional journey, especially in data science. Seek out experienced data professionals who inspire you, and express your interest in learning from them. A mentor can provide guidance, insights, access to a valuable network, and personalized support that can significantly benefit your career. Mentorship is a two-way street, often leading to mutually beneficial relationships that enrich the mentor and the mentee.
Use Social Media
In addition to LinkedIn, other social media platforms like Twitter can be helpful for networking in the data field. Follow data professionals, influencers, and relevant organizations. Engage in conversations, retweet, and share interesting content. Social media provides a more casual and interactive way to connect with others.
Leveraging Social Media for Networking in Data Science
In the digital age, social media platforms have evolved into powerful tools for networking and connecting with professionals in the data science field. Here’s an in-depth look at how you can maximize your use of social media for networking:
1. Broaden Your Reach: In addition to LinkedIn, explore platforms like Twitter, which offer a more casual and interactive approach to networking. By diversifying your social media presence, you can connect with a wider range of data professionals, influencers, and organizations.
2. Follow Data Professionals and Influencers: Start by identifying and following data professionals, industry influencers, thought leaders, and experts on social media platforms. Their posts, insights and shared content can provide knowledge, industry updates, and valuable connections.
3. Stay Informed: Social media is an excellent resource for staying informed about the latest trends, tools, and technologies in the data science field. By following and engaging with industry leaders, you’ll be privy to their expert opinions and insights into the rapidly evolving data landscape.
4. Engage in Conversations: Actively engage in conversations related to data science. Comment on posts, share your thoughts, ask questions, and participate in discussions. Contributing to these conversations allows you to showcase your knowledge, learn from others, and establish connections with like-minded individuals.
5. Share Valuable Content: Share interesting articles, research papers, blog posts, or insights related to data science. By consistently sharing valuable content, you position yourself as someone who is informed and engaged in the field. This can attract others who appreciate your contributions.
6. Retweet and Amplify: Retweet or share posts from data professionals and organizations that you find interesting or insightful. This spreads valuable information within your network and helps you connect with the original posters. It’s a way of showing appreciation and building rapport.
7. Participate in Twitter Chats and Hashtags: Many social media platforms, especially Twitter, host regular chats and discussions on specific data science topics using hashtags. Participate in these discussions to connect with experts and enthusiasts, learn from others, and share your insights.
8. Seek Advice and Guidance: Don’t hesitate to contact data professionals on social media if you have questions or seek advice. Many professionals are open to providing guidance and sharing their experiences, and social media offers a direct channel for these interactions.
9. Personal Branding: As you actively participate in discussions and share valuable content, you’ll build your brand within the data science community. Your online presence and contributions can make you more recognizable and memorable to potential collaborators and employers.
10. Networking Events: Social media platforms promote data science-related events, webinars, and conferences. Following these events and participating in their discussions can help you connect with fellow attendees and expand your network within the data community.
11. Be Authentic: Be yourself on social media. Authenticity is appreciated, and forming genuine connections with others is more likely when you are true to your voice and values.
In conclusion, social media platforms like Twitter offer a casual yet powerful means of networking within the data science field. By actively engaging with content, sharing your insights, and connecting with professionals and influencers, you can expand your network, stay informed, and open doors to a world of opportunities and collaborations in data science.
Attend Hackathons and Competitions
Hackathons and data science competitions are an exciting ways to meet like-minded individuals, showcase your skills, and collaborate on challenging projects. Join platforms like DataCamp, Topcoder, or HackerRank to find opportunities to compete and network with fellow participants.
Hackathons and Competitions: Catalysts for Networking and Skill Growth in Data Science
Participating in hackathons and data science competitions is a dynamic and immersive approach to networking within the data science community. These events provide an exciting skill development, collaboration, and professional network expansion platform. Here’s a detailed look at why these competitions are so valuable for networking:
1. Skill Development: Hackathons and data science competitions often present complex and real-world challenges. By participating in these events, you gain hands-on experience, apply your skills, and develop problem-solving techniques. This enhanced expertise builds your confidence and makes you a more attractive network contact.
2. Collaborative Opportunities: Most hackathons encourage collaboration. Forming teams and working with others allows you to leverage diverse skills and perspectives. Collaborators often become valuable connections for future projects or networking within the field.
3. Like-Minded Participants: Hackathons attract participants who share your passion for data science. These like-minded individuals can become your peers, collaborators, or mentors in the field. Building connections with individuals with a similar level of dedication to data science can be incredibly beneficial.
4. Competitive Edge: Successful participation in hackathons and competitions can distinguish you in the job market. Employers often value the problem-solving and teamwork skills developed in these environments. It can be a powerful addition to your professional portfolio.
5. Networking Events: Many hackathons and data science competitions feature networking events, Q&A sessions, or expert presentations. These events offer opportunities to connect with sponsors, judges, and fellow participants. Active participation in these activities can lead to meaningful connections.
6. Industry Recognition: Winning or performing well in prominent data science competitions can lead to industry recognition. Your achievements in these competitions can attract the attention of potential employers, collaborators, and mentors, ultimately expanding your network.
7. Online Platforms: Joining platforms like DataCamp, Topcoder, HackerRank, and Kaggle, or even participating in platforms like DrivenData offers you a gateway to a thriving community of data enthusiasts. These platforms host competitions and have forums, discussions, and profiles that enable networking and recognition.
8. Access to Industry Challenges: Many hackathons are sponsored by industry-leading companies and organizations. Participating in these events gives you insights into the challenges and projects relevant to these organizations. It can be a stepping stone to future job opportunities or collaborations.
9. Learning and Feedback: Hackathons provide continuous learning and feedback opportunities. Even if you don’t win, you can gain valuable feedback on your work, which can help you improve your skills and expand your network. Don’t hesitate to seek feedback from experienced participants.
10. Portfolio Building: The projects you complete during hackathons and competitions can be showcased in your professional portfolio. Sharing these achievements with potential collaborators, employers, or mentors can be a powerful conversation starter and networking tool.
11. Creativity and Innovation: These events often encourage participants to think creatively and innovatively. Engaging in such activities can help you develop a creative mindset that can benefit your career and make you more appealing to others.
In conclusion, hackathons and data science competitions are not just about winning prizes but also about the opportunities they offer for networking and skill growth. Active participation in these events can lead to collaborations, learning experiences, industry recognition, and lasting connections with like-minded individuals in the data science community.
Be Open to Informational Interviews
When you encounter data professionals whose work or career paths you admire, don’t hesitate to ask for informational interviews. These informal conversations can provide insights into their experiences, offer valuable advice, and potentially lead to future opportunities.
Embrace Informational Interviews: A Gateway to Insight and Opportunities in Data Science
Informational interviews are an often-underestimated tool for networking and personal growth in the data science field. These informal conversations can be incredibly valuable in providing insights, advice, and even future opportunities. Here’s an in-depth exploration of the benefits and strategies for making the most of informational interviews:
1. Gain Insights: Informational interviews offer a unique opportunity to gain insights into the experiences, paths, and challenges of data professionals you admire. You can learn from their journeys, achievements, and setbacks by asking thoughtful questions and actively listening.
2. Clarify Your Goals: These interviews can help you clarify your own career goals and the steps you need to take to achieve them. Through discussions with professionals who’ve walked a similar path, you can refine your own vision and develop a clearer plan.
3. Advice and Guidance: The data professionals you interview can provide valuable advice and guidance. Whether it’s about the skills you should prioritize, the organizations worth considering, or the best practices in the field, their input can be instrumental in your decision-making.
4. Expand Your Network: While the primary purpose of an informational interview is to gather insights, it can also lead to expanding your network. The professionals you interview may introduce you to others in the field, which can open doors to collaborations, job prospects, and mentorship.
5. Mutual Benefit: Informational interviews are a two-way street. They can mutually benefit you and the professional you’re speaking with. Sharing your experiences and goals can lead to reciprocal advice and potential collaborations.
6. Soft Skills Development: Engaging in informational interviews allows you to hone your communication and networking skills. These are transferable skills that are valuable not only in data science but in any professional setting.
7. Courting Mentorship: Informational interviews can be a stepping stone to mentorship. By building a rapport with a data professional, you may find a mentor willing to provide ongoing guidance and support in your career.
8. Personalization is Key: When requesting an informational interview, it’s crucial to personalize your outreach. Express why you admire their work or career and what specific insights you’re seeking. Make it clear that you value their time and expertise.
9. Prepare Thoughtful Questions: Prepare thoughtful and open-ended questions before the interview. Ask about their career journey, challenges, important milestones, and advice for someone aspiring to follow a similar path. Thoughtful questions demonstrate your genuine interest and respect.
10. Active Listening: During the interview, be an active listener. Pay close attention to the responses and ask follow-up questions. A meaningful conversation rather than a one-sided interrogation will leave a positive impression.
11. Show Gratitude: After the interview, express your gratitude for their time and insights. Send a thank-you email to acknowledge their help and reiterate your appreciation. This courteous gesture can leave a lasting positive impression.
In conclusion, informational interviews are a valuable tool for networking and personal growth in data science. By reaching out to data professionals you admire, engaging in thoughtful conversations, and building genuine connections, you can gain insights, refine your career goals, and potentially open doors to opportunities in the field. These interviews are not just about taking but about creating mutually beneficial connections within the data science community.
Conclusion
Networking with data professionals is essential for personal and professional growth in the data science field. By attending conferences, participating in online communities, collaborating on projects, and seeking mentorship, you can build a strong network that will advance your career and enhance your knowledge and skills. Networking is a two-way street, so be open to helping others. As you invest time and effort into building your network, you’ll find that the data community is full of passionate individuals eager to connect, share knowledge, and collaborate.
Today, we would like to highlight the functionality of Date Buckets, which is how we like to think of it mentally, and others call it Period-over-Period Analysis within Tableau Desktop. Both periods are buckets of dates and work great with min(1) kpi dashboards and often used in our Tableau Consulting engagements.
This blog delves into a method for date calculations to be used as trailing periods of time, to gain access to quick change between two periods in Tableau. In other words; We are focusing on identifying the last two periods in your data source, and the end user supplies a value to increase those buckets based on a date part you pick.
This approach enhances the efficiency and clarity of your analytical processes with Tableau and is easy to re-use. There are many ways to write this calculation and this is one way to write the calculation.
between dates filter
In Tableau this between date filter will create two calendar inputs, most executives don’t want to click anything.
It only takes 3 steps to build self generating, automated (not static set filters), date buckets in tableau desktop that trail with your max date in the date column [w].
lol, type this stuff or paste the code coming from this tutorial.
Below please find my quick win tutorial as a means of quickly winning… on any Tableau workbook with a date and a parameter.
We will be using the SuperStore Subset of data.
Which comes with every license of Tableau Desktop. In your data, you probably have a date. Use that date and follow along with these next two steps.
To begin, you need a date, and a parameter.
Step 1, make a date variable named W.
Create a new calculated field in tableau desktop, call it W.
make a simple variable W in place of your date. your date goes in this calculated field.
Now make the parameter.
Step 2, make a parameter variable named X. It’s an integer.
This will be the number of ‘X’ per period of analysis.
make a simple variable X in place of your parameter.
Paste the calculation below in any workbook with a Date and Parameter.
Above, if you followed along, you will not need to make any major changes to the calculation.
if DATETRUNC('month', [W])> DATEADD('month', -([X]+ datediff('month',{MAX([W])},today())) , TODAY()) then "Current Period" //make this 0 elseif DATETRUNC('month', [W])> DATEADD('month', -([X]*2+ datediff('month',{MAX([W])},today())) , TODAY()) then "Previous Period" //make this a 1 else "Filter" //make this a 2 END //[W] = date //[X] = parameter
Drag drop this on to the view, right click filter, filter filter…
Now, only two buckets of time are available. You’re welcome!
Automated period over period analysis in Tableau
You’ve just implemented automated date buckets in Tableau, allowing end-users to control visualizations using the bucket generator. Personally, I find the tool most effective when using it in a daily context rather than a monthly one. However, the monthly option provides a convenient way to encapsulate dates within distinct periods, while the daily granularity offers a simpler and more immediate view.
Having a rapid date divider or bucket automation at your disposal is highly advantageous. It empowers you to visually highlight disparities between two date periods or employ the calculations for logical flagging, subtracting values, and determining differences, all without relying on the software to construct these operations through window calculations.
Optimization date buckets or period over period in Tableau
Optimization #1: remove LOD calculations
Nothing against LOD calcs, except they are slow and built to help users who don’t know SQL.
{max(W)} seeks to find the max date, you can find it easier using a subquery in your select statement. If you don’t know what that means, ask your data architect supporting your environment to add the max(date) as a column, and have it be repeated per row too. They will know what to do or you need a new data architect.
Optimization #2: stop using % difference or difference table calculations
Nothing against table calculations, except they are slow and built to help users who don’t know SQL.
Optimization #3: change strings to integers.
Nothing against strings, except they are slow.
It’s likely not your fault that you’re using strings in 2018 with if statements, it’s probably because someone taught you who also did not know how to write optimized Tableau calculations.
Optimization #4: ‘month’ date part… add a swapper.
The Datetrunc is used to round the dates to the nearest relative date part, that’s just how I explain it easily.
Date part can be a parameter.
DATEPART(date_part, date, [start_of_week])
NO I Don’t mean the Function Datepart.
DATETRUNC(date_part, date, [start_of_week])
YES I Mean Date_part, which is scattered in the calculation and easy enough to replace with a parameter full of date_parts. Now end user can play a bit more.
Optimization #5: remove max(date), add an end date parameter…
Remove {max(date)} or the subquery of max(date) explained above because you can give your end user the opportunity to change the end date using parameter.
In today’s data-driven world, organizations are constantly seeking ways to gain a competitive edge and uncover hidden opportunities that can drive business growth. In this comprehensive guide, we will help you uncover hidden opportunities, which contain untapped growth potential through data analytics.
By harnessing the power of data, businesses can gain insights into customer behavior, market trends, and operational performance, enabling them to identify untapped opportunities and make informed, data-driven decisions. In this article, we explore how data analytics uncovers hidden opportunities and empowers organizations to unleash their growth potential.
In our client meetings, we’ve learned something important: the usual methods don’t always reveal an organization’s full potential. Excel, with all its data, and the fact that humans can make mistakes, can make things tricky. This is where advanced analytics consulting steps in, helping you improve how you manage data, and improve your overall data governance. Improving your data environment will begin to show you and others why using data analytics is a big deal for your business’s future success.
The Significance of Data Analytics in Business
In the rapidly evolving world of business, data analytics stands as an indispensable tool that catalyzes growth and fosters innovation. Its multifaceted significance extends across various domains, encompassing informed decision-making, competitive differentiation, customer-centricity, cost optimization, risk mitigation, innovation, scalability, and performance evaluation. By harnessing the power of data analytics, organizations can navigate the complexities of the modern business landscape with precision and foresight. In the sections that follow, we will delve into each of these facets, exploring how data analytics is pivotal to driving success in today’s dynamic environment.
Why is Data Analytics Important in Today’s Business Landscape?
In today’s dynamic and highly competitive business landscape, data analytics has emerged as a fundamental driver of success and innovation. Let’s delve deeper into why data analytics is not just important but absolutely crucial for businesses across industries:
Informed Decision-Making: Data analytics equips organizations with the ability to make informed decisions based on empirical evidence rather than intuition or guesswork. It provides insights into historical, current, and even predictive data, enabling leaders to choose strategies that are more likely to succeed. By analyzing data, businesses can identify trends, patterns, and correlations that may not be apparent through traditional analysis methods.
Competitive Advantage: Staying ahead of the competition is paramount in today’s cutthroat business world. Data analytics empowers companies to gain a competitive edge by identifying opportunities or gaps in the market that others might overlook. Through competitive analysis and real-time monitoring, organizations can swiftly adapt to changing market conditions, consumer preferences, and emerging trends.
Customer-Centric Approach: Understanding customer behavior and preferences is at the heart of every successful business. Data analytics allows companies to create comprehensive customer profiles, segment their audience, and personalize marketing efforts. This personalized approach enhances customer satisfaction, increases loyalty, and drives revenue growth.
Cost Reduction: Inefficient processes can eat into a company’s profit margins. Data analytics can uncover inefficiencies, bottlenecks, and areas where cost reductions are possible. By optimizing operations, businesses can save money, improve resource allocation, and enhance their bottom line.
Risk Mitigation: Every business faces risks, whether they be market fluctuations, supply chain disruptions, or cybersecurity threats. Data analytics can help identify potential risks early on, allowing organizations to take proactive measures to mitigate them. This proactive approach minimizes the impact of unforeseen events and helps maintain business continuity.
Innovation and Product Development: Data analytics provides valuable insights into customer feedback, market demands, and emerging trends. This information fuels innovation by helping organizations create products and services that truly resonate with their target audience. By understanding what customers want and need, companies can innovate more effectively and bring products to market that meet these demands.
Scalability and Growth: As businesses grow, managing and analyzing data becomes increasingly complex. Data analytics tools and techniques can scale with the organization, ensuring that valuable insights continue to be generated even as the volume of data increases. This scalability supports sustainable growth and expansion.
Accountability and Performance Measurement: Data analytics offers a way to measure and track performance metrics across all aspects of an organization. Whether it’s sales, marketing, operations, or customer service, data-driven KPIs enable businesses to assess their performance objectively and hold teams accountable for achieving goals.
In summary, data analytics is the cornerstone of modern business strategies. It empowers organizations to make data-driven decisions, gain a competitive edge, enhance customer relationships, reduce costs, manage risks, drive innovation, scale effectively, and measure performance accurately. To thrive in today’s business landscape, embracing data analytics isn’t just an option; it’s a necessity for long-term success and growth.
How can data analytics give organizations a competitive edge?
In the fiercely competitive business landscape of the 21st century, gaining a competitive edge is often the difference between success and stagnation. Data analytics has emerged as a formidable weapon in the arsenal of organizations seeking not just to survive but to thrive. Here’s a comprehensive look at how data analytics bestows a competitive advantage upon businesses:
Insight-Driven Decision-Making: Data analytics empowers organizations to make decisions rooted in concrete evidence rather than gut feeling. By analyzing historical and real-time data, businesses can uncover trends, patterns, and correlations that inform strategic choices. This data-driven decision-making minimizes risks and maximizes the likelihood of favorable outcomes.
Real-Time Adaptation: The business landscape is dynamic, with market conditions, consumer preferences, and industry trends constantly evolving. Data analytics enables organizations to monitor these changes in real time. This agility allows them to adapt swiftly to shifting circumstances, ensuring they are always one step ahead of competitors.
Customer-Centric Strategies: Understanding customers is key to success, and data analytics is the compass that guides this understanding. Through customer profiling, segmentation, and predictive analytics, organizations can tailor their offerings, marketing campaigns, and customer experiences. This personalization cultivates customer loyalty and sets businesses apart in a crowded market.
Cost Optimization: Inefficiencies can drain an organization’s resources. Data analytics shines a light on these inefficiencies, whether they exist in supply chains, operational processes, or resource allocation. By identifying areas for improvement, businesses can reduce costs and allocate resources more effectively, freeing up capital for growth initiatives.
Risk Mitigation: No business is immune to risks, but data analytics helps organizations identify potential risks early. Whether it’s market fluctuations, supply chain disruptions, or cybersecurity threats, proactive risk management strategies can be developed. This foresight enables organizations to mitigate risks, safeguard operations, and maintain business continuity.
Innovation and Product Enhancement: Data analytics reveals valuable insights from customer feedback, market trends, and emerging technologies. Armed with this knowledge, organizations can innovate efficiently. They can develop products and services that not only meet current demands but also anticipate future needs, positioning them as industry leaders.
Scalability and Growth: As organizations expand, so does the volume of data they generate and need to manage. Data analytics tools can scale with the business, ensuring that insights continue to flow even as operations grow. This scalability facilitates sustainable growth and market expansion.
Performance Measurement and Accountability: Data analytics provides a comprehensive suite of performance metrics that enable organizations to evaluate and track progress. This measurement capability extends across departments, from sales and marketing to operations and customer service. By holding teams accountable and setting clear objectives, organizations can optimize performance and drive continuous improvement.
In conclusion, data analytics is a potent catalyst for gaining a competitive edge in today’s business landscape. It empowers organizations to make informed decisions, adapt in real time, prioritize customers, optimize costs, mitigate risks, drive innovation, scale effectively, and measure performance accurately. To succeed in a world where every advantage matters, embracing data analytics isn’t merely an option; it’s a strategic imperative.
Analyzing Customer Behavior
HOW: Understanding customer behavior is a multidimensional pursuit that involves a combination of data analysis, psychology, and strategic thinking. It’s the process of unraveling the “how” behind why customers make the choices they do.
WHAT: At its core, analyzing customer behavior delves into the actions, preferences, and decision-making processes of consumers. It seeks to answer questions such as: What products do customers prefer? What factors influence their purchasing decisions? What channels do they use for research and buying? What are their pain points and desires?
WHY: The significance of analyzing customer behavior lies in the ability to decode the “why” behind consumer actions. By understanding the motivations and emotions driving customer behavior, businesses can tailor their strategies to create more compelling marketing campaigns, product offerings, and customer experiences. This not only enhances customer satisfaction but also drives revenue growth and positions organizations for long-term success.
With this framework in mind, let’s delve deeper into the strategies and techniques that enable businesses to decode the intricacies of customer behavior, beginning with the comparison of customer segmentation and predictive modeling.
What is the Significance of Understanding Customer Behavior?
Understanding customer behavior is the cornerstone of success in today’s hypercompetitive business landscape. It goes far beyond mere observation; it involves the systematic analysis of consumer actions, preferences, and motivations. Here’s why grasping the significance of customer behavior is paramount for any organization:
Informed Decision-Making: To make effective decisions, businesses must know their customers inside and out. Understanding customer behavior provides valuable insights into what drives purchasing decisions, which products or services resonate most, and how to optimize pricing, promotion, and distribution strategies. Armed with this information, organizations can make informed choices that align with customer preferences, increasing the likelihood of success.
Personalized Marketing: One-size-fits-all marketing is no longer effective. In today’s era, customers expect personalized experiences. Analyzing customer behavior allows businesses to segment their audience, tailoring marketing campaigns to specific groups with shared interests and needs. This personalization not only enhances customer engagement but also boosts conversion rates and customer loyalty.
Enhanced Customer Experience: Delving into customer behavior helps uncover pain points, preferences, and expectations. By addressing these insights, organizations can improve the customer experience, leading to higher satisfaction levels and increased customer retention. A satisfied customer is not only likely to return but also to advocate for the brand.
Competitive Advantage: In a crowded marketplace, understanding customer behavior is often the key differentiator. It allows businesses to anticipate market trends, adapt to changing consumer preferences, and stay ahead of competitors. Organizations that can harness customer insights are better positioned to seize opportunities and navigate challenges effectively.
Product and Service Innovation: Customer behavior analysis provides a wealth of ideas for innovation. By understanding what customers want and need, organizations can develop products and services that are better aligned with market demands. This fosters a culture of continuous improvement and keeps a business relevant and competitive.
Market Expansion: Beyond serving existing customers, understanding customer behavior can reveal opportunities for market expansion. It can help identify untapped customer segments with unmet needs. Armed with this knowledge, businesses can tailor their offerings to new markets or demographics, opening doors to new revenue streams and growth.
Cost Efficiency: By understanding customer behavior, businesses can allocate resources more efficiently. This means investing in areas that resonate most with customers while cutting back on less effective initiatives. It can lead to cost savings and a higher return on investment.
In conclusion, understanding customer behavior is not just a business strategy; it’s a strategic imperative. It underpins data-driven decision-making, empowers personalized marketing, enhances customer experiences, fosters innovation, provides a competitive edge, opens doors to market expansion, and optimizes resource allocation. Organizations that recognize the significance of customer behavior are better positioned to thrive in today’s ever-evolving business landscape.
Customer Segmentation vs. Predictive Modeling: Which is More Effective?
In the realm of understanding customer behavior, two powerful analytical approaches stand out: customer segmentation and predictive modeling. Both methods are invaluable for gaining insights into consumer actions and preferences. However, determining which is more effective often depends on the specific goals and challenges a business faces. Let’s explore each approach in depth, shedding light on their respective strengths and applications.
Customer Segmentation: The Power of Grouping
Customer Segmentation Defined: Customer segmentation involves dividing a customer base into distinct groups based on shared characteristics, behaviors, or preferences. The goal is to create segments of customers who are similar in certain ways, making it easier to tailor marketing strategies and products to each group’s specific needs.
Advantages of Customer Segmentation:
Personalization: Customer segmentation allows businesses to personalize their marketing efforts. By understanding the unique preferences and needs of each segment, organizations can create targeted campaigns and product offerings that resonate with specific customer groups.
Enhanced Customer Engagement: Tailored communication and offers make customers feel understood and valued. This, in turn, fosters higher levels of engagement and customer loyalty.
Efficient Resource Allocation: Businesses can allocate resources more efficiently by focusing on high-potential customer segments. This leads to better marketing ROI and cost savings.
Market Expansion: Customer segmentation can uncover new segments with unmet needs. Businesses can identify and tap into previously undiscovered markets, expanding their reach and revenue potential.
Predictive Modeling: Anticipating Future Behavior
Predictive Modeling Defined: Predictive modeling leverages historical data and statistical algorithms to forecast future customer behavior. It’s about identifying patterns and trends that can be used to make informed predictions about what customers are likely to do next.
Advantages of Predictive Modeling:
Proactive Decision-Making: Predictive modeling allows businesses to be proactive rather than reactive. By anticipating customer behavior, organizations can implement strategies to meet future needs and challenges.
Cross-Selling and Upselling: Predictive models can identify opportunities for cross-selling or upselling to existing customers. By understanding what additional products or services customers are likely to be interested in, businesses can boost revenue.
Risk Mitigation: Predictive models can assess the risk associated with various customer actions, such as credit risk or churn risk. This helps organizations take preventive measures to mitigate potential issues.
Personalization at Scale: While customer segmentation offers personalization within predefined segments, predictive modeling allows for personalization at an individual level. This level of granularity can be particularly effective in industries like e-commerce.
Which is More Effective?
The effectiveness of customer segmentation versus predictive modeling depends on the specific objectives and resources available to a business. In many cases, a combination of both approaches is the most effective strategy. Customer segmentation can guide high-level marketing and product development strategies, while predictive modeling can provide actionable insights for individual customer interactions and long-term planning.
In essence, the choice between customer segmentation and predictive modeling should not be a matter of “either/or” but rather a thoughtful integration of both methods. By doing so, businesses can create a holistic approach to understanding and influencing customer behavior, ultimately driving growth and success in today’s competitive marketplace.
How Analyzing Customer Behavior Enhances Personalized Marketing Strategies
In the digital age, personalized marketing has become a cornerstone of effective engagement and customer satisfaction. Central to this strategy is the analysis of customer behavior. By delving into how customers interact with your brand, you gain the insights needed to tailor your marketing efforts in ways that resonate deeply with your audience. In this section, we explore how analyzing customer behavior acts as the catalyst for enhancing personalized marketing strategies, forging stronger connections with your customers and driving meaningful results.
Analyzing Customer Behavior for Personalized Marketing
Understanding customer behavior is the golden key to unlocking the power of personalized marketing strategies. By delving into the intricacies of how customers interact with your brand, you can create tailored experiences that resonate on a profound level. Let’s explore how this approach works and why it’s essential for modern businesses.
The Insight into Individual Preferences
At the heart of personalized marketing is the ability to understand each customer’s unique preferences. This isn’t just about knowing names; it’s about diving into the specifics of what makes each customer tick. Through careful analysis of customer actions – from browsing history to purchase patterns – businesses can paint a vivid picture of individual likes, dislikes, and interests.
Segmentation: The Magic of Grouping
Segmentation is like organizing your audience into tribes of shared interests. It’s a powerful technique that allows you to group customers based on behaviors, preferences, or past interactions. Imagine tailoring your marketing efforts to distinct segments – sports enthusiasts receiving promotions related to sporting events while home decor lovers enjoy special offers on interior design products.
Perfect Timing for Maximum Impact
Timing is everything in marketing. Analyzing customer behavior helps pinpoint the ideal moments for marketing interactions. Imagine sending a personalized product recommendation right after a customer has expressed interest – this impeccable timing greatly boosts the message’s relevance, increasing the chances of conversion.
Unleashing Cross-Selling and Upselling
Analyzing customer behavior uncovers opportunities for cross-selling and upselling. By understanding what products or services a customer is interested in, businesses can suggest complementary or premium items. This not only increases the average transaction value but also showcases a deep understanding of the customer’s needs.
Crafting Content with Personalization
Content is the currency of modern marketing. Armed with insights into customer interests, businesses can craft content that speaks directly to individual needs and preferences. This personalized content not only captures attention but also forges a stronger emotional connection with the audience.
Rescuing Abandoned Carts
Cart abandonment is a common challenge in e-commerce. Customer behavior analysis can trigger retargeting efforts – like sending a friendly reminder email with the abandoned cart’s contents. This encourages customers to reconsider and complete their purchase, reducing cart abandonment rates.
Loyalty Programs with a Personal Touch
Understanding the drivers behind repeat purchases empowers businesses to design loyalty programs tailored to individual preferences. Some customers may be motivated by discounts, while others might prefer exclusive offers or early access to new products. Personalized loyalty programs create a sense of exclusivity and reward, deepening customer relationships.
The Continuous Feedback Loop
Customer behavior analysis is an ongoing process. It includes gathering feedback directly from customers, giving them a platform to express their opinions and concerns. This valuable feedback loop allows businesses to continuously refine their personalized strategies, ensuring they remain aligned with changing customer preferences.
In essence, analyzing customer behavior serves as the compass for crafting personalized marketing strategies that resonate with individuals. It empowers businesses to understand preferences, segment audiences effectively, time interactions for maximum impact, spot opportunities for cross-selling, create engaging content, rescue abandoned carts, foster customer loyalty, gather invaluable feedback, and perpetually enhance their approaches. In a world where customers crave tailored experiences, behavior analysis isn’t just a competitive edge; it’s the cornerstone of modern marketing success.
What are the benefits of tailoring product offerings based on customer insights?
Tailoring product offerings to align with customer insights isn’t just a strategic choice; it’s a customer-centric paradigm shift that can yield remarkable benefits for businesses. Let’s delve into why this approach is so valuable and the advantages it brings:
Enhanced Customer Satisfaction: Understanding customer preferences and needs allows businesses to design products that align perfectly with what their target audience desires. When customers find products that resonate with their tastes, they are more likely to be satisfied with their purchases. This satisfaction leads to higher levels of customer loyalty and advocacy, as happy customers tend to become brand advocates who recommend products to others.
Improved Customer Retention: Offering products tailored to customer preferences fosters a sense of loyalty. When customers feel that a brand understands and caters to their unique needs, they are less likely to switch to competitors. This leads to improved customer retention rates, reducing the need for costly acquisition efforts to replace lost customers.
Increased Sales and Revenue: Products that align with customer insights are more likely to be well-received in the market. This can result in increased sales and revenue. Customers are more inclined to make purchases when they perceive that a product directly addresses their specific pain points or desires. Furthermore, cross-selling and upselling opportunities become more effective when products are closely matched to customer preferences.
Competitive Differentiation: In crowded marketplaces, offering products tailored to customer insights can set a business apart from competitors. It sends a clear message that the company listens to its customers and prioritizes their needs. This differentiation can be a significant competitive advantage, attracting customers who are looking for personalized solutions.
Reduced Inventory Costs: Tailoring product offerings based on customer insights can lead to a more efficient inventory management system. Businesses can stock items that are in higher demand and reduce the inventory of less popular products. This minimizes carrying costs and the risk of overstocking or understocking.
Lower Marketing Costs: Personalized products often require less aggressive marketing campaigns. When a product resonates strongly with a specific customer segment, marketing efforts can be more targeted and cost-effective. This optimization of marketing resources can result in substantial cost savings.
Innovation Opportunities: Customer insights provide valuable ideas for product innovation. By understanding what customers want or need, businesses can identify opportunities to create entirely new products or features. This innovation not only drives sales but also positions the business as an industry leader.
Data-Driven Decision-Making: Tailoring product offerings based on customer insights is a data-driven approach. It encourages businesses to rely on empirical evidence rather than intuition or guesswork. This approach fosters a culture of data-driven decision-making throughout the organization, which can lead to better outcomes in various aspects of the business.
Better Inventory Turnover: Products that are tailored to customer preferences tend to have higher turnover rates. Items are more likely to be sold quickly, reducing the time they spend in storage. This is particularly important in industries with perishable or seasonal goods.
In conclusion, tailoring product offerings based on customer insights is a strategic move that can lead to higher customer satisfaction, improved retention rates, increased sales and revenue, competitive differentiation, cost savings, innovation opportunities, data-driven decision-making, and better inventory turnover. It’s a customer-centric approach that not only meets customer expectations but also positions businesses for long-term success and growth in today’s highly competitive markets.
Benefit
Example
Enhanced Customer Satisfaction
Offering eco-friendly products to environmentally-conscious customers.
Improved Customer Retention
A subscription service offering customized skincare products.
Increased Sales and Revenue
A bookstore suggesting personalized book recommendations.
Competitive Differentiation
A clothing brand providing custom sizing for a perfect fit.
Reduced Inventory Costs
A grocery store adjusting stock based on seasonal demand.
Lower Marketing Costs
An online retailer sending personalized email offers.
Innovation Opportunities
A tech company launching a new smartphone with user-requested features.
Data-Driven Decision-Making
A restaurant using customer feedback data to adjust its menu.
Better Inventory Turnover
A fashion boutique offering limited-edition designs based on customer feedback.
This table breaks down the benefits of tailoring product offerings based on customer insights, and real-world examples to illustrate how businesses can leverage these advantages.
How does understanding customer behavior lead to identifying new market segments?
Understanding customer behavior goes beyond serving current customers—it can also unlock the potential to expand into new market segments. By examining how existing customers interact with your products or services, you can identify similarities and patterns that indicate the existence of untapped markets. Let’s delve into this concept with a table that breaks down the process:
Table 1: Steps to Identifying New Market Segments Through Customer Behavior Analysis
Step
Explanation
1. Customer Behavior Analysis
Begin by analyzing the behavior of your existing customers. Look at their demographics, preferences, and behaviors.
2. Identify Patterns
Look for patterns and commonalities among customer segments. Are there shared interests, needs, or pain points?
3. Define New Segments
Based on identified patterns, define potential new market segments that align with the observed customer behaviors.
4. Market Research
Conduct market research to validate the existence and viability of these potential segments.
5. Tailor Products or Services
Adapt your products or services to cater to the unique needs and preferences of the new segments.
6. Targeted Marketing
Develop targeted marketing campaigns to reach the newly identified segments, addressing their specific interests.
7. Monitor and Adjust
Continuously monitor the response of the new segments and adjust your strategies based on feedback and performance.
This table provides a comprehensive step-by-step guide for businesses to leverage customer behavior analysis as a strategic tool to identify and tap into new market segments. The table outlines how to initiate the process by analyzing customer behavior, spotting patterns, defining potential market segments, conducting market research for validation, adapting products or services, launching targeted marketing campaigns, and maintaining a dynamic approach through monitoring and adjustments.
Example: Identifying New Market Segments Through Customer Behavior
Imagine you operate a fitness app and have a diverse customer base. Your customer behavior analysis reveals that a significant portion of your users is particularly interested in yoga and meditation content. They engage with these features more frequently than other aspects of the app. Here’s how the process might unfold:
Table 2: An Illustrative Scenario – Example of Identifying and Targeting a New Market Segment
Step
Explanation
1. Customer Behavior Analysis
You analyze user data and find that a substantial number of users regularly participate in yoga and meditation sessions.
2. Identify Patterns
You notice that these users tend to have similar demographic profiles – they are health-conscious and seek relaxation.
3. Define New Segments
You define a new market segment: “Mindful Wellness Enthusiasts” based on their shared interests in yoga and meditation.
4. Market Research
You conduct surveys and gather market data to confirm the demand for mindfulness and wellness-related offerings.
5. Tailor Products or Services
You expand your app’s content to include more yoga and meditation resources, catering specifically to this new segment.
6. Targeted Marketing
You launch marketing campaigns highlighting the app’s new features to reach and engage the Mindful Wellness Enthusiasts.
7. Monitor and Adjust
You continuously track user engagement and gather feedback to refine your offerings and marketing strategies.
In this table, we present a practical example that demonstrates how a fitness app operator utilizes customer behavior analysis to discover and engage a previously untapped market segment, “Mindful Wellness Enthusiasts.” The table outlines each step of the process, from recognizing user behavior patterns centered around yoga and meditation to conducting market research, tailoring product offerings, launching targeted marketing efforts, and continuously refining strategies based on user feedback, showcasing the real-world application of customer behavior insights in expanding market reach and relevance.
By understanding customer behavior and identifying the “Mindful Wellness Enthusiasts” segment, you’ve uncovered a new market opportunity and tailored your product to serve their specific needs, potentially expanding your user base and revenue streams. This approach highlights the power of customer behavior analysis in identifying and capitalizing on untapped market segments.
Identifying Market Trends
In today’s fast-paced and ever-evolving business landscape, the ability to identify, understand, and respond to market trends is paramount for organizational success. Market trends encompass shifts in consumer preferences, technological advancements, industry dynamics, and competitive landscapes. Failing to recognize and adapt to these trends can leave businesses vulnerable to obsolescence or missed opportunities.
However, with the advent of data analytics and the wealth of information available, organizations can now harness the power of data-driven insights to not only spot trends but also position themselves strategically for sustainable growth and competitiveness.
In this exploration, we delve into the critical importance of identifying market trends, the role of data analytics in this endeavor, the significance of competitor analysis, the advantages of early market entry based on data insights, and how businesses can leverage trend analysis to navigate the complex terrain of modern markets.
Why is it crucial for organizations to identify market trends?
Identifying market trends is crucial for organizations because it allows them to stay competitive and adapt to changing consumer preferences and industry dynamics. Market trends provide insights into what customers want, how the market is evolving, and where opportunities lie. By recognizing and understanding these trends, businesses can make informed decisions that help them remain relevant and profitable in a rapidly changing business environment.
How can data analytics help in spotting trends and anticipating shifts?
Data analytics is a powerful tool for spotting trends and anticipating shifts in the market. By collecting and analyzing vast amounts of data, businesses can identify patterns and correlations that may not be apparent through traditional methods. Advanced analytics techniques, such as predictive modeling and machine learning, can forecast future trends based on historical data, consumer behavior, and various market indicators. This enables organizations to make proactive decisions, adjust their strategies, and capitalize on emerging opportunities while minimizing risks.
What role does competitor analysis play in identifying market trends?
Competitor analysis is an essential component of identifying market trends. By studying competitors’ actions, strategies, and performance, organizations can gain valuable insights into the evolving landscape of their industry. Tracking competitors helps identify emerging trends and customer preferences, as well as gaps in the market that competitors may have missed. This information can inform a company’s own strategies, helping them differentiate themselves and respond effectively to changes in the market.
What are the advantages of entering new markets early based on data-driven insights?
Entering new markets early based on data-driven insights offers several advantages. First and foremost, it allows businesses to establish a strong foothold and build brand recognition before competitors do. This early-mover advantage can lead to increased market share and long-term profitability.
Additionally, entering new markets early based on data-driven insights enables companies to tailor their products or services to meet local consumer needs and preferences effectively. This localization can lead to higher customer satisfaction and loyalty, ultimately driving revenue growth.
Moreover, early market entry provides an opportunity to forge strategic partnerships, secure advantageous distribution channels, and gain valuable experience in the new market, all of which can further solidify a company’s position and competitive advantage.
How can businesses position themselves strategically using market trend analysis?
Market trend analysis allows businesses to position themselves strategically in several ways:
Product and Service Development: By aligning their offerings with current market trends and consumer demands, businesses can develop products or services that resonate with their target audience.
Marketing and Messaging: Tailoring marketing campaigns and messaging to highlight alignment with prevailing trends can attract and engage customers more effectively.
Resource Allocation: Businesses can allocate resources, such as marketing budgets and research and development funds, to areas that are likely to yield the highest returns based on trend analysis.
Risk Mitigation: Identifying potential disruptors or threats early allows businesses to proactively address challenges and reduce risks to their operations.
Expansion Strategies: Market trend analysis can inform decisions about entering new markets, expanding product lines, or diversifying offerings to capitalize on emerging opportunities.
Competitive Positioning: Understanding market trends relative to competitors enables businesses to position themselves as leaders or differentiators in the industry.
In summary, market trend analysis empowers businesses to make data-driven decisions that enhance their competitiveness, profitability, and long-term sustainability in a dynamic and ever-evolving market landscape.
What is Optimizing Operational Performance?
Optimizing Operational Performance refers to the process of systematically improving various aspects of an organization’s operations to enhance efficiency, productivity, and overall effectiveness. This optimization can encompass a wide range of activities, processes, and functions within the organization and is aimed at achieving specific objectives, such as reducing costs, increasing revenue, improving customer satisfaction, or streamlining processes.
How to Optimize Operational Performance:
Data Analysis: The first step in optimizing operational performance is often collecting and analyzing data related to various aspects of the organization’s operations. This data can include production metrics, customer feedback, financial performance, and more. Data analysis helps identify areas where improvements are needed.
Identifying Bottlenecks and Inefficiencies: Through data analysis and process mapping, organizations can pinpoint bottlenecks, inefficiencies, and areas of waste in their operations. These could include redundant tasks, slow processes, or resource misallocation.
Process Redesign: Once problem areas are identified, organizations can redesign processes to eliminate bottlenecks and inefficiencies. This may involve streamlining workflows, automating repetitive tasks, or reorganizing teams.
Technology Adoption: Embracing technology can play a crucial role in optimizing operational performance. This may involve implementing new software systems, adopting data analytics tools, or incorporating automation and robotics into production processes.
Employee Training and Engagement: Employees are often at the heart of operational performance. Providing training, encouraging skill development, and fostering a culture of continuous improvement can significantly impact performance optimization.
Why Optimize Operational Performance:
Cost Reduction: Optimization can lead to cost savings by eliminating wasteful processes, reducing resource consumption, and improving resource allocation.
Enhanced Productivity: Streamlined operations and improved processes often result in increased productivity, allowing organizations to accomplish more with existing resources.
Competitive Advantage: Optimized operations can give organizations a competitive edge by delivering products or services faster, with higher quality, or at a lower cost compared to competitors.
Customer Satisfaction: Improved operations often lead to better customer experiences. Timely delivery, quality products, and efficient customer service contribute to higher levels of customer satisfaction.
Profitability: Ultimately, operational optimization is often pursued to increase profitability. By reducing costs and enhancing revenue generation, organizations can improve their bottom line.
In summary, optimizing operational performance involves a systematic approach to improving various aspects of an organization’s processes and activities. It’s a critical endeavor for organizations looking to thrive in today’s competitive business environment by becoming more efficient, cost-effective, and responsive to customer needs.
Organizations are inundated with vast amounts of information that serve as the lifeblood of their operations. Whether it’s customer data, financial records, or market insights, harnessing and trusting your data is paramount. Data governance can be used to ensure that data remains accurate, reliable, and secure.
Data governance is often overlooked as a low priority, common sense, but without working through the best practices, companies often adopt inefficient workflows that don’t solve important problems. This guide will delve into the world of data governance, and help you create short and long term success in you data ecosystem. This blog will help you explore various roles, answer questions, and provide best practices to help maintain data integrity in your data environment.
In this comprehensive data governance guide, we’ll delve into the world of data governance, learn about data governance, explore roles, answer questions, and explore best practices that may help you maintain data integrity in your data environment.
Data is essential for businesses of all sizes. It is used to make decisions, improve efficiency, and develop new products and services. However, data can also be a liability if not managed properly. This is where data governance comes in.
Data governance is managing data availability, usability, integrity, and security throughout its lifecycle. It is a system of policies, procedures, and roles ensuring data is used correctly and responsibly.
What is Data Governance?
Data Governance refers to the framework, policies, and practices organizations implement to manage their data assets effectively. Many lean on similar terms and rewrite their data governance documentation identically to other companies.
Data environments are not created equally; data governance should evolve as your data environment and solution capability update. For example, your data governance should become if you have someone who can offer data science, machine learning, or AI.
Data governance may start to help encompass fuzzy concepts and offer a window into operationalizing the data environment with various categories: data quality, security, compliance, accessibility, and more, explained verbose below.
A well-established data governance strategy is the cornerstone of data integrity and starts with documenting your data governance data strategy right now.
You can use this comprehensive guide to establish your own custom Data Governance Practice and know this is an excellent base-level standard that many organizations worldwide are working towards establishing. Data practices, data governance, data strategies, and data management are still relatively new in the grand scheme of things,, so be mindful that most people have never considered this topic in an organization that has never discussed data governance at a company scale.
Data governance is the set of practices organizations employ to manage their data assets effectively.
Data governance is essential for ensuring the reliability, accuracy, security, and accessibility of data within an organization.
Data governance establishes the rules, policies, and guidelines that govern how data is collected, stored, processed, and shared.
In this article, you will learn a lot about Data Governance and empirical observations we have gained over the past decade of consulting clients.
What could happen if we don’t implement Data Governance?
Imagine running a complex organization without clear rules or a roadmap. Without Data Governance discussed at a high level, it’s easy to generate many problems like data inaccuracy, causing manual manipulation of the data before decisions can be made, or long projects with teams across many silos, which often take weeks to months to complete because no data governance model is in place.
Also, data silos are generated as trust begins to shift between each team, and no single source of truth is relevant due to a lack of data warehousing practices.
As a data warehousing consulting company we spend a lot of time helping data silos transition to single sources of truth. Questions to answers becomes a puzzle with missing pieces, and making decisions becomes a gut feeling.
Information is vulnerable, operations around data are often inefficient, and growth opportunities are missed.
The consequences are real without data governance, ranging from data chaos to security risks.
Eleven compelling reasons why data governance is not just a good idea but a necessity.
Each reason highlights data governance’s vital role in ensuring data is accurate, secure, and used effectively for informed decision-making and business success.
Data Inaccuracy: Without data governance, data may become inconsistent, inaccurate, or incomplete. This can lead to poor decision-making based on faulty information. When one user has one bad experience, they tell three other users. Avoiding bad experiences increases adoption.
Data Silos: Data may be scattered across various departments or systems, creating data silos. This hinders collaboration and sharing of information, slowing down processes and decision-making. Data silos create poor data cultures and create competitive data resources, where “trust” of other silos’ data resources becomes a juggle between not wanting to depend on software for accuracy or someone else’s spreadsheet for accuracy.
Compliance Issues: Failure to adhere to data regulations and compliance standards can result in legal consequences, fines, and damage to your organization’s reputation. Companies like being in certain compliances based on their state and country or employees live in.
Security Vulnerabilities: Data may lack proper security measures, making it vulnerable to breaches and cyberattacks. This can lead to data theft and significant financial losses. If your company is hacked often, having low data governance practices around data security may increase your risk; begin with storing private data in a different location as your public data resources.
Operational Inefficiencies: Inefficient data handling processes can lead to wasted time and resources, hindering productivity and increasing operating costs.
Confusion and Errors: Inconsistent data definitions and procedures can cause confusion among employees and lead to errors in data handling and analysis. Confusion leads to lowered adoption, and errors should be handled in the testing phases. Errors lead to decreased trust and lowered adoption; no strategy around managing errors will lead to more problems. Webhook scenario: when webhooks fail, your reporting system is out of sync; containing this error helps improve data accuracy.
Missed Opportunities: Without proper data governance, you may miss opportunities to use data strategically for business growth, innovation, and optimization. Not knowing the % chance X increased by 2000% VS last month can make a big difference in EOQ.
Customer Trust Erosion: Mishandling customer data or failing to protect it can erode trust, leading to customer dissatisfaction and loss of business. Losing customers internally or externally is terrible news, and your technical development is because of technical debt, also known as shelf-ware.
Resource Misallocation: Resources may be misallocated, leading to unnecessary spending on data management or technology that doesn’t align with organizational goals. Not talking about how people put data into software today may unnecessarily lead to too many resources inputting data into software.
Data Waste: Data may accumulate without apparent retention and disposal policies, resulting in data bloat and increased storage costs.
Lack of Accountability: Without defined roles and responsibilities, no one may take ownership of data quality, leading to a lack of accountability.
In essence, not implementing data governance can result in many negative consequences, including data-related inefficiencies, security risks, compliance issues, and missed opportunities for growth and innovation. It’s essential to recognize the value of data governance in ensuring that data remains an asset rather than a liability within your organization.
Why is Data Governance Important?
Data governance is important because it helps organizations handle their data cleverly and organize it.
In its simplest form, data governance is how organizations manage their data wisely and effectively. It’s like having a set of rules and tools to ensure data is accurate, safe, and helpful in making decisions and achieving goals. Imagine a world where data is like puzzle pieces, and data governance ensures all the pieces fit perfectly. In this world, data is protected from digital thieves, and everyone uses the same rulebook. It’s a world where finding information is as easy as picking up a suitable toy, and data helps organizations grow and serve their customers better. Let’s explore why data governance is so important by looking at 11 key reasons, each making data management more transparent and beneficial for businesses and individuals.
Better Data Quality: Imagine having a puzzle with missing pieces or pieces that don’t quite fit. Data governance ensures that your data is accurate and complete, like having all the pieces for a perfect puzzle. This objective data is crucial for making good decisions.
Following the Rules: You know how there are rules for driving or playing games? Similarly, there are rules (laws and regulations) for handling data, incredibly personal or sensitive information. Data governance helps organizations follow these rules to avoid trouble.
Protecting Your Secrets: Think of data like a treasure chest; some of that data is like hidden treasure. Data governance puts locks on the chest and sets guards to protect your valuable data from thieves or hackers.
Getting Things Done Faster: Imagine trying to build a sandcastle with a spoon. It would take forever! Data governance ensures you have the right tools and methods to work with data efficiently, like having a bucket and shovel to build that sandcastle quickly.
Avoiding Confusion: Have you ever played a game where everyone uses different rules? It’s chaos! Data governance ensures that everyone in the organization understands and uses the same rules for data. This avoids confusion and mistakes.
Making Decisions with Confidence: When you have all the facts and know they’re accurate, you can confidently make decisions. Data governance ensures that the information you use for decision-making is trustworthy.
Saving Resources: Picture having lots of toys scattered everywhere. It’s hard to find what you need, right? Data governance helps tidy up and organize your data so you don’t waste time and money looking for it.
Matching Goals: Just like a GPS helps you reach your destination, data governance ensures that using data supports your organization’s goals and plans. It helps keep everyone on the same path.
Taking Responsibility: Everyone has a role to play in a group project. Data governance assigns roles and responsibilities to people who care for the data, ensuring it’s handled properly.
Unlocking Value: Data can be like a hidden treasure chest. Data governance helps you open that chest and find valuable information that can be used to make your organization better or even create new products or services.
Building Trust: When you share your secrets with someone, you trust them not to tell anyone else. Similarly, when organizations handle data responsibly, customers trust them more, which is essential in businesses like shopping or healthcare.
Data governance is like having rules and tools to ensure your data is accurate, safe, and valuable. It helps organizations work more efficiently, make better decisions, and protect helpful information.
What is the difference between Data Strategy and Data Governance?
Data Strategy and Data Governance are two distinct but closely related concepts in data management, each with its focus and objectives. Here’s a breakdown of the key differences between them:
Data Strategy Focus
The primary focus of a data strategy lies in crafting a roadmap that guides an organization’s long-term vision and objectives concerning its data assets. It’s akin to setting the compass that will steer the organization toward achieving its broader goals through the strategic utilization of data. Here’s a more detailed breakdown of this focal point:
Long-Term Vision: At the core of a data strategy’s focus is the development of a clear and forward-looking vision for data. This vision extends beyond immediate needs and strives to anticipate how data can contribute to the organization’s growth, sustainability, and future relevance. It envisions data as a long-term strategic asset.
Strategic Utilization: Data is not merely viewed as a passive resource but as an active agent in pursuing business objectives. A data strategy outlines how data will be actively and strategically utilized to advance the organization’s interests. This may involve leveraging data for market expansion, customer engagement, product development, or process optimization.
Business Goals Alignment: The data strategy aligns data initiatives with the broader business strategies of the organization. It ensures that data-related efforts are synchronized with overarching objectives, reinforcing that data is a critical driver for achieving these goals.
Innovation Catalyst: A data strategy fosters innovation by providing the groundwork for experimenting with data-driven approaches. It encourages a culture of experimentation and learning, where data is a source of insights that can lead to novel solutions, product enhancements, or disruptive innovations.
Competitive Edge: Data strategy recognizes that data is an asset and a source of competitive advantage. It outlines how data can be used to gain an edge in the market, whether through improved customer experiences, predictive analytics, or data-driven decision-making that outpaces competitors.
Data Monetization: As part of its broader perspective, a data strategy considers opportunities for data monetization. This involves exploring how data can be transformed into revenue streams by selling products, licensing data access, or creating data-driven services.
Continuous Adaptation: Focusing on long-term objectives means that a data strategy also considers the evolving nature of data and technology. It includes mechanisms for adaptability, ensuring that the strategy remains relevant and responsive to changing data landscapes and business dynamics.
In essence, the focus of a data strategy transcends mere data management; it encompasses a strategic mindset that treats data as a valuable asset that can propel the organization into the future. It’s about charting a course where data isn’t just a resource but a potent force that shapes the organization’s destiny, fostering innovation and delivering a sustainable competitive edge.
Data Governance Focus
Data governance constitutes the operational and tactical backbone of an organization’s data management efforts. It is chiefly concerned with the day-to-day intricacies of data management, ensuring that data remains accurate, secure, compliant, and usable. Here’s an in-depth exploration of this key focus:
Data Quality Assurance: The unwavering commitment to data quality is at the heart of data governance. It strongly emphasizes maintaining data accuracy, consistency, and reliability. This involves implementing processes and mechanisms to detect and rectify data errors, inconsistencies, and duplications.
Security Fortification: Data governance prioritizes data security as a foundational principle. It establishes safeguards and controls to protect data from unauthorized access, breaches, and cyber threats. This includes defining access permissions, encryption protocols, and data masking techniques to shield sensitive information.
Regulatory Compliance: Data governance’s central focus is ensuring compliance with data-related regulations. It involves staying abreast of evolving data protection laws and industry standards and implementing practices that align with these requirements. This includes managing data consent, data subject requests, and data protection impact assessments.
Usability Enhancement: While data governance is rigorous in its approach to data management, it also seeks to make data accessible and usable. It aims to balance robust data security and ensure authorized users can access and utilize data effectively for decision-making and operational purposes.
Roles and Responsibilities: A pivotal aspect of data governance is delineating roles and responsibilities. It defines who within the organization is accountable for data stewardship, data ownership, and data management. These roles ensure that data governance is a collaborative effort with clear lines of responsibility.
Policy Formulation: Data governance entails the creation of policies and guidelines that govern data management practices within the organization. These policies cover data access, retention, sharing, and disposal, among other aspects. They serve as a framework for consistent and compliant data handling.
Process Implementation: Data governance establishes standardized processes for data management. It outlines how data is collected, processed, stored, and archived. These processes help maintain data quality, integrity, and traceability throughout its lifecycle.
Continuous Improvement: Data governance is a dynamic practice. It focuses on continuous improvement by regularly assessing data management practices, identifying areas for enhancement, and adapting to changing data requirements, technologies, and regulatory landscapes.
Data Stewardship: Central to data governance is the concept of data stewardship, where individuals or teams are responsible for overseeing specific datasets. Data stewards play a crucial role in data quality control, tracking data lineage, and ensuring data policy adherence.
Data Access Control: Data governance defines access controls and permissions to determine who can access, modify, or use specific datasets. This ensures that data is only accessible to authorized personnel while adhering to the principle of least privilege.
In essence, the focus of data governance is on the meticulous management of data assets to ensure their quality, security, compliance, and usability on a day-to-day basis. It establishes the operational framework and safeguards necessary to protect data’s integrity while facilitating its strategic utilization within the organization. Data governance is the guardian that ensures data remains a reliable and valuable asset throughout its journey within the organization.
Data Strategy Objectives: The central goal of a data strategy is to harness data as a valuable asset for driving business growth, fostering innovation, and facilitating transformative change. It outlines specific objectives, priorities, and initiatives aimed at optimizing the organization’s data resources to the fullest extent.
Data Governance Objectives: Data governance primarily aims to ensure that data is consistently accurate, reliable, secure, and compliant with relevant regulations. Its objectives revolve around sustaining data quality, mitigating data-related risks, and providing a structured framework for data management within the organization.
Data Strategy Scope: The scope of a data strategy is expansive, encompassing various aspects like data architecture, data analytics, data integration, and data monetization. It takes into account how data can strategically benefit the organization across multiple dimensions.
Data Governance Scope: In contrast, data governance has a narrower scope, focusing on the day-to-day operational facets of data management. This includes activities like data stewardship, data quality control, data access control, and compliance management.
Data Strategy Time Horizon: A data strategy often adopts a forward-looking perspective, extending its time horizon over several years. It seeks to define the organization’s long-term data-related goals and priorities, anticipating future needs and trends.
Data Governance Time Horizon: Data governance operates within a more immediate time frame. It is concerned with the current data management practices and ensuring that they align with the organization’s strategic data objectives in the short to mid-term.
Data Strategy Responsibilities: Responsibility for developing and overseeing the data strategy typically rests with senior management and data strategists. They assume the role of setting the direction for how data will be leveraged to achieve the organization’s overarching goals.
Data Governance Responsibilities: Data governance distributes responsibilities across various stakeholders, including Data Stewards, Data Owners, and data management teams. These stakeholders are accountable for implementing and enforcing data policies and standards to ensure effective data management within the organization.
In summary, while both data strategy and data governance are essential components of effective data management, they serve different purposes. Data strategy defines the high-level vision and objectives for data usage, while data governance provides the framework and processes for managing data effectively to achieve those strategic goals. They work together to ensure that an organization not only leverages data strategically but also maintains data quality, security, and compliance throughout its lifecycle.
How will AI reshape Data Governance?
In the ever-evolving landscape of data management and security, one question looms large: How will AI reshape Data Governance? As organizations grapple with the growing complexities of data handling, artificial intelligence emerges as a powerful force poised to revolutionize the way we safeguard and manage our digital treasures. In this exploration of AI’s transformative potential, we delve into a series of groundbreaking possibilities that could redefine the very essence of data governance. From automating discovery and enhancing quality to fortifying security and predicting future challenges, AI is poised to usher in a new era of data governance, one that promises efficiency, security, and unparalleled insights. Yet, as we embark on this AI-driven journey, we must navigate carefully, mindful of the ethical and human considerations that underscore this technological evolution. Join us as we embark on this transformative odyssey through the realm of AI-powered Data Governance.
AI has the potential to significantly reshape data governance in several ways:
Data Discovery and Classification: AI can automate the process of discovering and classifying data. Machine learning models can analyze data content to determine its sensitivity, value, and compliance requirements. This helps organizations identify and tag sensitive or regulated data more efficiently.
Data Quality and Cleansing: AI can enhance data quality by automating data cleansing and validation processes. It can identify and rectify inconsistencies, errors, and duplications in datasets, leading to more accurate and reliable data.
Data Access Control: AI-driven systems can enforce fine-grained access control policies. AI can analyze user behavior and contextual data to dynamically adjust access permissions, reducing the risk of unauthorized data access.
Data Masking and Anonymization: AI can help protect sensitive data through advanced techniques such as data masking and anonymization. Machine learning models can generate synthetic data that retains the statistical properties of real data while preserving privacy.
Data Encryption: AI can improve encryption strategies by optimizing encryption key management and enhancing encryption algorithms. This ensures that data remains secure during transmission and storage.
Data Privacy Compliance: AI can assist organizations in complying with data privacy regulations like GDPR and CCPA. It can automate processes for data subject requests, consent management, and data protection impact assessments.
Threat Detection and Prevention: AI-powered anomaly detection systems can continuously monitor data access and usage patterns, alerting organizations to potential security breaches or insider threats in real-time.
Data Retention and Lifecycle Management: AI can help organizations manage data retention policies more effectively by analyzing data usage patterns and regulatory requirements. This ensures that data is retained for the appropriate duration and securely disposed of when necessary.
Data Governance Automation: AI-driven platforms can automate many aspects of data governance, including policy enforcement, auditing, and reporting. This reduces the burden on human data stewards and improves overall efficiency.
Predictive Analytics for Governance: AI can provide predictive insights into data governance. It can forecast potential data governance issues, such as compliance violations or data quality degradation, allowing organizations to take proactive measures.
Natural Language Processing (NLP) for Compliance Documents: NLP algorithms can analyze and extract relevant information from legal documents and compliance regulations, helping organizations better understand and implement data governance requirements.
Continuous Monitoring and Auditing: AI can continuously monitor data environments and audit data usage for compliance and security violations. This real-time monitoring reduces the risk of non-compliance and data breaches.
However, it’s essential to approach AI-driven data governance with caution. Organizations must ensure transparency, fairness, and ethical considerations in AI algorithms, especially when dealing with sensitive data. Additionally, human oversight and expertise remain crucial in designing and maintaining effective data governance strategies in the AI era.
Who is Responsible for Data Governance in Your Organization?
Data governance is a multifaceted and intricately woven tapestry that constitutes a cornerstone of modern organizational dynamics. It stands as a testament to the intricate interplay of various organizational roles, each assigned a distinctive yet interrelated responsibility, akin to individual threads meticulously woven into the fabric of an elaborate tapestry. In this symphonic orchestration of data stewardship, the harmonious coexistence of these roles is essential, akin to a finely tuned orchestra where every instrument contributes its unique notes to create a harmonious composition.
Within the orchestration of data governance, several individuals shoulder pivotal responsibilities. You may need to create, edit, or delete roles to fit your organization to ensure deadlines are kept.
What role does a Data Steward play in Data Governance?
Within the realm of data governance, Data Stewards play a pivotal and technically rigorous role. These individuals are entrusted with the meticulous custodianship of specific data domains, where their responsibility extends far beyond the surface. They serve as the unwavering sentinels of data quality, diligently engaged in the nuanced craft of preserving data accuracy, consistency, and completeness.
Data Stewards are akin to skilled artisans, employing their expertise to curate and safeguard the integrity of the data under their purview. Their work involves rigorous data profiling, validation, and the relentless pursuit of data perfection. They meticulously examine data to ensure it aligns with established quality standards and conforms to predefined rules and guidelines.
One of their core functions is to detect anomalies and rectify data discrepancies promptly. This meticulous attention to detail ensures that the data remains an unassailable bastion of trust within the organization. Their vigilance extends to monitoring data changes, conducting root cause analyses for data issues, and implementing corrective actions.
Data Stewards are instrumental in ensuring that data remains an asset rather than a liability. They collaborate closely with data owners, data custodians, and other stakeholders to enforce data governance policies and uphold the organization’s data quality standards. By doing so, they contribute to the creation of a data environment where data is reliable, consistent, and invaluable for making informed decisions.
How do Data Stewards work within my organization?
In the ever-evolving landscape of modern organizations, the role of Data Stewards emerges as a linchpin in the realm of data management and governance. These diligent custodians of data are integral to ensuring that your organization harnesses the full potential of its data assets. As we explore the intricate web of “How do Data Stewards work within my organization?” you will discover the pivotal ways in which Data Stewards collaborate with various teams, enhancing data quality, compliance, and the overall data-driven decision-making culture, ultimately steering your organization toward excellence.
Collaborative Data Insights: Data Stewards can collaborate closely with Data Analysts to provide them with meticulously curated datasets, ensuring that analysts have high-quality data to derive valuable insights from.
Data Governance Advocacy: Data Stewards act as advocates for data governance practices within an organization, educating and working with other teams, like IT and business units, to ensure adherence to data quality standards.
Seamless Integration: Data Stewards work hand-in-hand with Data Engineers to facilitate the integration of diverse data sources. Their expertise ensures that data is ingested, transformed, and stored in a manner that maintains its quality and integrity.
Effective Reporting: Data Stewards partner with Business Intelligence (BI) teams to define data quality metrics and standards, helping BI professionals create accurate and reliable reports and dashboards.
Data Compliance Support: Collaborating with Compliance and Legal teams, Data Stewards help ensure data conforms to regulatory requirements and is handled in a way that complies with data privacy laws.
Data User Training: Data Stewards assist in training end-users, including sales and marketing teams, on how to effectively use and interpret data, promoting data literacy across the organization.
Data-driven Decision Support: By working closely with Decision Makers, Data Stewards ensure that decision-makers have access to trustworthy data, enabling informed and data-driven decision-making.
Data for Product Development: Collaborating with Product Managers, Data Stewards can provide clean, reliable data that supports product development and innovation efforts.
Customer Experience Enhancement: Data Stewards collaborate with Customer Support and Experience teams to ensure that customer-related data is accurate, leading to improved customer service and satisfaction.
Risk Mitigation: Partnering with Risk Management teams, Data Stewards help identify and mitigate data-related risks, ensuring that the organization is safeguarded against data quality and compliance issues.
Data Stewards: Champions of Data Governance in Modern Organizations
Data Stewards are essential to the success of any data-driven organization. They collaborate with various teams across the organization to enhance data quality, compliance, and the overall data-driven decision-making culture. Data Stewards play a pivotal role in developing and implementing data governance policies and procedures, monitoring and improving data quality, ensuring data compliance, and promoting a data-driven culture. By working closely with various teams and implementing effective data governance practices, Data Stewards can help organizations to improve their decision-making, increase efficiency, and achieve their strategic goals.
Data Stewards are the linchpins of data governance in modern organizations. They help organizations to harness the full potential of their data assets and navigate the complex challenges and opportunities of the digital age.
Who is a Data Owner in Data Governance?
In the realm of data governance, Data Owners play a pivotal role as architects, shaping the narrative of data within their designated domains. They wield significant authority, allowing them to define how data is used, craft access rights, and establish the overarching storyline of data within their realms.
Data Owners preside over specific data territories with a sense of responsibility akin to strategic decision-makers in data management. They determine the purpose and relevance of data within their purview, aligning it with the organization’s objectives and operational needs. This involves not just a surface-level understanding but a profound comprehension of how data can serve as a strategic asset.
One of their core functions is to establish access controls and permissions, deciding who within the organization can access, modify, or utilize specific datasets. Striking a balance between enabling data-driven decision-making and safeguarding data against unauthorized or inappropriate usage is central to their role. It requires a nuanced understanding of data security and compliance requirements, which they must implement effectively.
Data Owners collaborate closely with Data Stewards to ensure data quality and integrity are maintained within their domains. They establish data usage policies, defining the rules and guidelines for how data should be handled, utilized, and retained. This collaboration is essential to uphold the reliability of data, as Data Stewards are experts in data quality management.
The role of a Data Owner extends beyond data governance; it involves a deep understanding of data’s significance in the organization’s operations. They act as advocates for data-driven decision-making, actively seeking opportunities to leverage data assets for strategic advantage. This includes identifying new ways in which data can contribute to innovation, efficiency, and improved customer experiences.
Often holding leadership positions, Data Owners bridge the gap between technical data management and strategic business objectives. They are instrumental in ensuring that data remains a valuable asset that aligns seamlessly with the organization’s mission. Their role makes data governance a proactive force in achieving organizational success, where data is not just managed but harnessed to drive excellence across all aspects of the organization.
How do Data owners work with others around my organizations?
In the intricate landscape of modern organizations, data has emerged as a prized asset, a currency of unparalleled value. It permeates every facet of our operations, guiding strategic decisions, enhancing customer experiences, and fueling innovation. Amid this data-driven paradigm, the role of Data Owners stands as a linchpin, orchestrating the harmonious integration of data throughout the organization. In this exploration, we delve into the pivotal role of Data Owners and their collaborative efforts with various teams within the organization. These stewards of data navigate the complexities of data management, ensuring it remains a strategic asset that aligns seamlessly with the organization’s mission. Join us on this journey as we uncover the multifaceted collaborations that underscore the significance of Data Owners in the modern business landscape.
Collaborative Data Strategy: Data Owners work closely with the leadership and strategy teams to align data usage and management with the organization’s overall objectives, ensuring data serves as a strategic asset.
Business Unit Integration: They collaborate with various business units to understand their unique data needs and challenges, ensuring that data is tailored to support specific operational goals.
Technical Teams Coordination: Data Owners liaise with IT and data engineering teams to implement technical solutions that facilitate effective data management, integration, and access.
Data Quality Assurance: They partner with Data Stewards to maintain and enhance data quality, ensuring that data remains reliable and trustworthy for all teams.
Security and Compliance: Data Owners work closely with compliance and security teams to ensure data privacy and regulatory compliance are maintained throughout the organization.
Cross-functional Training: They assist in training end-users, including sales, marketing, and product development teams, on how to effectively use data to achieve their goals.
Data-Driven Decision Support: By collaborating with decision-makers and analytics teams, Data Owners ensure that data is readily available for informed and data-driven decision-making.
Product Development: Data Owners collaborate with product managers to provide clean, reliable data that supports the development of new products and features.
Customer Experience Enhancement: They work with customer support and experience teams to ensure that customer-related data is accurate, contributing to improved service and satisfaction.
Risk Mitigation: Partnering with risk management teams, Data Owners help identify and mitigate data-related risks, ensuring the organization is safeguarded against data quality and compliance issues.
In conclusion, the role of Data Owners within an organization cannot be overstated. These individuals serve as the custodians of an organization’s most valuable asset: its data. Through their expertise, collaboration, and strategic acumen, Data Owners ensure that data remains a powerful driver of success. By harmonizing data across diverse teams, safeguarding its quality and integrity, and aligning it with strategic objectives, Data Owners contribute significantly to informed decision-making, improved customer experiences, and the overall excellence of the organization.
In an era where data is the lifeblood of modern business, Data Owners are the guardians of its sanctity and significance. Their ability to bridge the gap between technical data management and strategic business goals transforms data governance from a mere necessity into a proactive force for organizational achievement. As we navigate the ever-evolving data landscape, the importance of Data Owners shines brightly as they continue to shape the narrative of data within our organizations, driving us toward unparalleled success.
What is a Data Governance Committee?
The Data Governance Committee is the linchpin of the overarching data governance framework. This distinguished assembly of governance luminaries operates as the conductors of a highly intricate data governance symphony, orchestrating the harmonious integration of data governance policies and practices throughout the organization.
Much like seasoned conductors guiding a symphony orchestra, the Data Governance Committee navigates the multifaceted landscape of data governance with finesse and precision. Their role extends to bridging gaps, synchronizing efforts, and ensuring a seamless alignment with the strategic compositions and objectives of the organization.
The Committee is tasked with setting the strategic direction of data governance initiatives, ensuring they align with the organization’s overarching goals. They define the scope of data governance, establish governance policies and guidelines, and oversee the implementation of these principles across various business units and data domains.
One of the Committee’s primary functions is to act as a liaison between the technical aspects of data governance and the organization’s leadership. They facilitate communication and collaboration between Data Stewards, Data Owners, and other stakeholders, ensuring that data governance practices are understood and embraced at all levels.
In addition to their strategic role, the Data Governance Committee assumes responsibility for monitoring the effectiveness of data governance practices. They conduct regular assessments, audits, and reviews to identify areas for improvement and verify that data governance policies and standards are being consistently applied.
The Committee is composed of individuals with deep expertise in data governance, data management, compliance, and business strategy. Their diverse backgrounds and knowledge contribute to a holistic and balanced approach to data governance, where technical rigor meets strategic vision.
In essence, the Data Governance Committee serves as the guiding force that harmonizes data governance efforts throughout the organization. Their leadership ensures that data remains a valuable and strategically aligned asset, fostering a culture of data-driven decision-making and organizational excellence.
In this beautifully orchestrated ballet of responsibilities, data governance unfurls like an opulent tapestry. It relies upon the seamless synchronization of roles, where each participant’s contribution, akin to the harmonic notes in an orchestral composition, adds depth, coherence, and resonance to the organization’s data management practices. Together, these individuals compose a masterpiece where data’s value is preserved, its sanctity upheld, and its purpose realized in the symphony of organizational success.
How does the Data Governance Committee work within my organization?
The importance of establishing a Data Governance Committee within your organization cannot be overstated. This distinguished assembly of experts serves as the linchpin of the overarching data governance framework, operating as the conductors of a highly intricate data governance symphony. In much the same way that seasoned conductors guide a symphony orchestra to produce harmonious music, the Data Governance Committee navigates the multifaceted landscape of data governance with finesse and precision. Their role extends to bridging gaps, synchronizing efforts, and ensuring a seamless alignment with the strategic compositions and objectives of the organization.
As we delve into the importance of having a Data Governance Committee, we will explore the ten key ways in which this committee collaborates with other teams within your organization to foster a culture of data-driven decision-making and organizational excellence.
Strategic Alignment: The Data Governance Committee collaborates closely with other teams to ensure that data governance initiatives align with the organization’s strategic goals and objectives.
Policy Development: They work with Legal and Compliance teams to develop data governance policies and guidelines that comply with regulations and best practices, ensuring these policies are understood and followed across the organization.
Communication Bridge: Acting as liaisons, the Committee facilitates communication between technical teams, such as Data Stewards and Data Owners, and leadership, fostering a shared understanding of data governance practices at all levels.
Collaborative Oversight: The Committee oversees the implementation of data governance principles across various business units and data domains, ensuring that data is managed consistently and effectively.
Performance Monitoring: They monitor the effectiveness of data governance practices through assessments, audits, and reviews, identifying areas for improvement and verifying consistent application of policies and standards.
Cross-Functional Expertise: Comprising members with expertise in data governance, management, compliance, and strategy, the Committee brings diverse backgrounds to the table, contributing to a holistic and balanced approach to data governance.
Data Quality Assurance: They collaborate with Data Stewards and Quality Assurance teams to maintain and enhance data quality, ensuring that data remains reliable and trustworthy.
Data Privacy Compliance: In partnership with Privacy and Security teams, the Committee helps ensure data privacy compliance and secure data handling practices across the organization.
IT Integration: The Committee works with IT teams to integrate data governance tools and technologies, ensuring seamless implementation and technical support for governance initiatives.
Advocacy for Data-Driven Culture: By promoting data-driven decision-making and organizational excellence, the Committee encourages teams throughout the organization to leverage data as a strategic asset, contributing to overall success.
What are Data Users in relationship to Data Governance?
Data Users represent the skilled navigators who traverse the intricate pathways of organizational data with precision and expertise. They are the discerning connoisseurs, the individuals who understand that data is not just raw information but a wellspring of potential insights. Within the data governance ecosystem, Data Users embody the principles of data governance in action.
Guided by meticulous governance guidelines, Data Users approach data with intent and purpose. They recognize that data, when wielded with precision, has the potential to shape decisions, refine strategies, and drive innovation. Data Users are, in essence, the craftsmen of data-driven decision-making within the organization.
One of the fundamental responsibilities of Data Users is to extract meaningful insights from data. They employ a range of analytical tools and methodologies to transform data into actionable information. This involves data exploration, visualization, statistical analysis, and machine learning techniques, among others. By doing so, they craft a symphony of well-informed decisions that resonate throughout the organization.
Data Users understand that data governance isn’t just a set of rules but a pathway to empowerment. They appreciate the importance of data quality and reliability, recognizing that the trustworthiness of insights hinges upon the integrity of the underlying data. Therefore, they collaborate closely with Data Stewards and Data Owners to ensure that data quality standards are upheld.
Furthermore, Data Users champion data literacy within the organization. They actively promote a culture where individuals across departments understand and appreciate the value of data. This advocacy extends to training and educating colleagues on how to effectively use data in their roles, fostering a data-savvy workforce.
In summary, Data Users are the embodiment of data-driven decision-making within the organization. They navigate the data landscape with finesse, seeking profound insights, and translating them into actionable strategies. Guided by the principles of data governance, they contribute to the organization’s success by crafting melodies of insight and efficacy from the symphony of data.
Who are the Data Custodians in data governance?
Rooted in the technical intricacies of data governance, Data Custodians are the unsung heroes, the master craftsmen of data infrastructure. They are entrusted with the monumental responsibility of ensuring that the very foundations upon which data governance stands remain robust, secure, and resilient.
At the heart of their role lies the meticulous construction and maintenance of data storage systems. Data Custodians are responsible for the architectural design, deployment, and day-to-day operation of data storage solutions. These solutions must not only provide adequate capacity but also ensure the accessibility, availability, and reliability of data.
Security is a paramount concern for Data Custodians. They stand as sentinels against threats to data integrity, unauthorized access, and data breaches. This entails the establishment of formidable security measures, including access controls, encryption protocols, and intrusion detection systems. They continuously monitor data systems to safeguard sensitive information from external and internal threats.
Data Custodians also play a pivotal role in data lifecycle management. They oversee the archival and deletion of data, ensuring that data is retained for the appropriate duration and disposed of securely when no longer needed. This process aligns with data governance policies and legal requirements, minimizing data-related risks.
In the dynamic world of data governance, where technology evolves rapidly, Data Custodians stay abreast of emerging trends and best practices. They are responsible for implementing advanced technologies and techniques that enhance data storage, retrieval, and security. This adaptability ensures that the organization’s data infrastructure remains robust and aligned with industry standards.
Moreover, Data Custodians are instrumental in preserving data lineage and documentation. They maintain comprehensive records of data storage configurations, backup procedures, and disaster recovery plans. These records provide essential context and understanding of data infrastructure, contributing to transparency and accountability within the data governance framework.
In essence, Data Custodians serve as the guardians of data infrastructure, ensuring its resilience and security. Their role is pivotal in safeguarding data’s accessibility and integrity within the organizational framework, providing a solid foundation upon which data governance derives its structural integrity.
What Are the Key Components of Data Governance?
Data governance involves a range of essential components, each carefully designed to play a crucial role in managing data resources effectively. These components act like building blocks, coming together to create a framework that gives data meaning and purpose in the organization. In this exploration of data governance’s architectural elements, we’ll delve into how these key components work together, each serving a vital role in ensuring data is managed effectively.
Ensuring Data Integrity: Data Quality in Data Governance
Data quality is the cornerstone of effective data governance. It encompasses a set of processes and practices aimed at ensuring that data is of the highest accuracy, consistency, and completeness.
Data Quality refers to the degree to which data is accurate, reliable, consistent, and fit for its intended purpose within an organization. It encompasses various aspects of data, including its completeness, accuracy, consistency, timeliness, and relevancy. Data quality is essential because high-quality data is more trustworthy, helps make better-informed decisions, supports effective business operations, and reduces the risk of errors or misinterpretations.
Data governance plays a pivotal role in maintaining data quality through several key mechanisms:
Data Profiling: Data governance facilitates the systematic examination of data to identify anomalies, inconsistencies, and errors. Profiling involves analyzing data values, data types, and data patterns to gain insights into data quality issues.
Data Validation: Data governance establishes validation rules and checks that data must adhere to. These rules ensure that data entering the organization’s systems meets predefined quality standards. Any data that fails validation is flagged for correction or rejection.
Data Cleansing: When discrepancies in data are detected, data governance defines processes for data cleansing. This involves correcting errors, resolving inconsistencies, and filling in missing data elements. Cleansed data is then reintegrated into the organization’s data ecosystem.
High data quality is paramount for multiple reasons. It enhances trust in data, enabling stakeholders to rely on data for critical decision-making. Inaccurate or incomplete data can lead to costly errors, from misguided business strategies to compliance violations. By maintaining data quality through data governance, organizations can ensure that their data is a valuable asset rather than a liability.
Component
Description
Data Profiling
In-depth analysis to understand data quality issues, anomalies, and patterns.
Data Cleansing
Automated processes to correct errors, remove duplicates, and enhance data accuracy.
Data Auditing
Regular audits to track changes, ensure compliance, and maintain data quality standards.
Navigating Regulatory Waters: Compliance in Data Governance
In an era of evolving data regulations and heightened privacy concerns, compliance with data-related laws and standards is non-negotiable. Data governance serves as the lynchpin for ensuring that an organization adheres to various regulatory requirements, including but not limited to GDPR, HIPAA, and industry-specific mandates.
Data governance achieves compliance through several mechanisms:
Policy Development: It involves the creation of data policies that outline the organization’s stance on data handling, privacy, and security. These policies align with regulatory requirements and set clear expectations for data management practices.
Data Auditing: Regular data audits, as part of data governance, examine data practices to ensure that they conform to established policies and standards. Auditing also identifies areas of non-compliance that require corrective action.
Data Protection Measures: Data governance establishes robust security measures to safeguard sensitive data. This includes access controls, encryption, and data masking techniques that prevent unauthorized access or data breaches.
Documentation and Reporting: Data governance emphasizes the importance of maintaining records and documentation related to data handling. This documentation serves as evidence of compliance efforts and supports reporting to regulatory bodies when necessary.
Non-compliance with data regulations can lead to significant financial penalties, legal repercussions, and reputational damage. Data governance mitigates these risks by promoting a culture of compliance within the organization, ensuring that data is collected, processed, and stored in accordance with the law.
Component
Description
Regulatory Framework
Comprehensive understanding of relevant data regulations and compliance requirements.
Data Classification
Categorization of data based on sensitivity, ensuring appropriate handling and protection.
Privacy Impact Assessments
Assessments to evaluate and address privacy risks associated with data processing activities.
Fortifying the Digital Fort Knox: Security in Data Governance
Data breaches can have profound and far-reaching consequences for organizations. They can result in financial losses, damage to reputation, and legal liabilities. Data governance is instrumental in addressing these security challenges through robust security measures:
Access Controls: Data governance defines access controls that restrict data access to authorized personnel only. Access privileges are granted based on job roles and responsibilities, ensuring that sensitive data is not exposed to unnecessary risks.
Encryption: Data governance mandates the use of encryption to protect data both in transit and at rest. Encryption algorithms ensure that even if data is intercepted or stolen, it remains unintelligible without the corresponding decryption keys.
Regular Auditing: Auditing is a fundamental aspect of data governance security. It involves continuous monitoring of data access and changes, allowing organizations to detect and respond to security incidents promptly.
Data Masking: Data governance includes techniques like data masking, which involve replacing sensitive data with fictional or scrambled values. This ensures that even within the organization, access to sensitive information is restricted to those who genuinely require it.
Data governance’s security measures create a robust defense against data breaches and unauthorized access. They help organizations safeguard sensitive data, maintain customer trust, and uphold their reputation in an era where data security is of paramount importance.
Component
Description
Access Controls
Implementation of role-based access controls (RBAC) to restrict data access to authorized users.
Encryption
Utilization of encryption techniques for data at rest and in transit to safeguard against breaches.
Security Monitoring
Employment of intrusion detection systems and real-time monitoring to detect and respond to security threats.
Streamlining Operations: Efficiency in Data Governance
Efficiency is a core benefit of data governance. It streamlines data-related processes, making data easier to find, access, and use. This efficiency is critical for organizations looking to optimize their operations:
Data Catalogs: Data governance often involves the creation of data catalogs or inventories. These catalogs provide a comprehensive view of available data assets, making it easier for users to locate relevant data quickly.
Metadata Management: Metadata, which provides context and information about data, is a focus of data governance. By effectively managing metadata, organizations can reduce the time spent searching for data and increase its usability.
Data Lineage: Data governance establishes data lineage, which tracks the origin, transformations, and movements of data. This lineage helps users understand data’s history and trust its accuracy.
Efficient data governance reduces redundancy, eliminates data silos, and ensures that data is readily accessible to those who need it. As a result, organizations can make faster, data-driven decisions, respond more rapidly to changing business conditions, and enhance their overall productivity.
Component
Description
Data Automation
Automation of data ingestion, transformation, and validation processes for efficiency.
Data Cataloging
Implementation of data catalog solutions to streamline data discovery and access.
Data Lifecycle Management
Definition of clear policies for data retention, archiving, and disposal to optimize storage resources.
Informed Choices: Decision-Making in Data Governance
Data-driven decision-making is a strategic advantage in today’s business landscape. Data governance plays a critical role in fostering trust in data and providing the necessary structure for informed decision-making:
Data Lineage and Transparency: Data governance establishes clear data lineage, showing how data is collected, processed, and transformed. This transparency instills confidence in the data’s accuracy and reliability.
Data Quality Assurance: Through data governance processes like data profiling and validation, data quality is assured. Decision-makers can rely on data to be accurate and consistent, reducing the risk of making decisions based on flawed information.
Consistency and Standardization: Data governance enforces data standards and consistency across the organization. This ensures that data is presented in a uniform manner, facilitating easier comparison and analysis.
Data governance transforms data into a strategic asset, empowering decision-makers to make data-informed choices. It replaces intuition and guesswork with data-backed insights, leading to more effective strategies, improved operational efficiency, and competitive advantages in the marketplace.
Component
Description
Data Analytics
Leverage data analytics tools and techniques to extract insights for informed decision-making.
Data Governance Metrics
Establishment of key performance indicators (KPIs) to measure the effectiveness of data governance efforts.
Data Access Reporting
Provision of reports on data access, usage, and compliance for transparency to decision-makers.
Maximizing Resource Potential: Resource Optimization in Data Governance
Resource optimization is a tangible benefit of data governance. By governing data effectively, organizations can streamline data management processes and allocate resources more efficiently:
Data Inventory: Data governance often involves creating a comprehensive data inventory. This inventory helps organizations identify redundant or obsolete data, reducing storage costs and freeing up valuable resources.
Data Lifecycle Management: Data governance defines data lifecycle processes, including archiving and deletion policies. This ensures that data is retained only for as long as necessary, reducing the resources required for long-term data storage.
Resource Allocation: By understanding data usage patterns and data importance, organizations can allocate resources more effectively. They can prioritize resources for critical data assets while reducing investment in less critical ones.
Resource optimization through data governance leads to cost savings, better resource allocation, and improved operational efficiency. It ensures that data management practices align with the organization’s strategic objectives.
Component
Description
Resource Allocation
Effective allocation of data governance resources considering roles, technology, and budget.
Data Virtualization
Implementation of data virtualization to reduce redundancy and optimize data storage.
Scalability Planning
Planning for future growth by ensuring data governance processes can scale to meet increased demands.
Unleashing Data’s Value: Data Monetization in Data Governance
For many organizations, data is not just an operational asset but a potential source of revenue. Data governance is instrumental in unlocking the value of data assets by ensuring data quality, compliance, and security:
Data Quality and Trust: High-quality data, ensured through data governance, is essential for monetization efforts. Reliable data builds trust with customers and partners, increasing the perceived value of data offerings.
Compliance and Data Sharing: Data governance ensures that data sharing practices comply with legal and regulatory requirements. This is crucial when selling or sharing data externally, avoiding legal risks and ensuring ethical data use.
Data Packaging and Marketing: Effective data governance can help package and market data offerings effectively. This includes defining data product catalogs, pricing strategies, and data delivery mechanisms.
Monetizing data assets can create new revenue streams for organizations, driving growth and diversification. Data governance provides the necessary infrastructure and assurance required for successful data monetization initiatives.
In conclusion, data governance is not merely a set of rules and policies; it’s a strategic framework that underpins an organization’s data-related efforts. Its impact is far-reaching, from ensuring data quality and compliance to enhancing security, efficiency, decision-making, and resource optimization. Moreover, it enables organizations to unlock the potential value of their data assets, opening doors to data monetization opportunities in an increasingly data-centric world.
These key components, like masterfully composed movements in a symphony, harmoniously interact to create a robust data governance framework. They provide the structural scaffolding and guidance necessary to sustain the integrity of data, thereby facilitating astute decision-making and propelling the organization toward the realization of its overarching goals.
Component
Description
Data Commercialization Strategy
Development of a strategy for monetizing data through product offerings or partnerships.
Data Pricing Models
Determination of pricing models for data products or services based on market demand and value.
Data Monetization Compliance
Ensuring that data monetization practices align with data privacy and regulatory requirements.
How Does Data Governance Relate to Data Management?
Data governance and data management are closely related concepts, each playing a distinct but interconnected role in the effective handling of data:
Data Governance: Data governance defines the overarching framework of policies, processes, and practices that guide the management of data. It establishes the rules, standards, and guidelines that data management activities should follow. Data governance sets the strategic direction for how an organization manages and uses its data assets.
Data Management: Data management, on the other hand, involves the day-to-day operational aspects of handling data. It encompasses tasks such as data collection, storage, processing, analysis, and reporting. Data management follows the guidelines and policies set by data governance to ensure data quality, security, and compliance.
In essence, data governance sets the direction, while data management executes those directives. While data governance provides the strategic framework and rules for responsible data handling, data management ensures that these rules are implemented consistently and effectively in everyday data-related activities.
A successful data ecosystem requires both components to work in harmony. Data governance establishes the vision and policies, while data management brings that vision to life through practical implementation.
What Are the Challenges of Implementing Data Governance?
Implementing data governance can present various challenges that organizations need to address:
Organizational Resistance: Employees may resist changes in data handling practices, especially if they perceive them as disruptive to established workflows. Resistance can hinder the adoption of data governance practices.
Complexity: Data governance can be complex, involving multiple components, policies, and stakeholders. Successfully implementing and managing these complexities may require significant planning, resources, and expertise.
Data Silos: Many organizations struggle with data silos, where data is isolated in different departments or systems. Overcoming these silos and ensuring data consistency across the organization can be challenging.
Lack of Awareness: Some employees may not fully understand the importance of data governance or the specific policies and practices in place. Education and awareness programs are necessary to ensure that everyone in the organization understands and follows data governance guidelines.
Regulatory Changes: The landscape of data regulations is constantly evolving. Staying updated and ensuring that data governance practices remain compliant with new and changing regulations can be a continuous challenge.
Despite these challenges, the benefits of data governance, such as improved data quality, compliance, and security, outweigh the initial difficulties. Addressing these challenges through clear communication, training, and ongoing monitoring is essential for successful data governance implementation.
What are Best Practices for Data Governance?
Define Clear Objectives and Goals: Setting clear objectives and goals is the foundational step in effective data governance. It’s essential to determine what you aim to achieve through your data governance efforts. Are you primarily focused on improving data quality to enhance decision-making? Are you striving for compliance with data privacy regulations? Having well-defined objectives provides a clear roadmap for your data governance initiatives, ensuring that your efforts are aligned with your organization’s strategic priorities.
Establish Data Ownership and Accountability: Assigning ownership and accountability for data governance tasks is crucial. Without clear responsibility, data governance can become fragmented and ineffective. Designate specific individuals or teams responsible for data governance tasks, including data quality assurance, security, and compliance. This ensures that someone is directly accountable for maintaining data integrity and aligns with the principle that “if everyone is responsible, no one is responsible.”
Data Classification and Categorization: Not all data is equal in terms of its sensitivity and importance. Data governance best practices include categorizing data based on its attributes, such as sensitivity, criticality, and usage. This classification helps determine the level of governance required for each data category. For example, highly sensitive customer data may require stricter governance measures than non-sensitive operational data. Categorization guides resource allocation and prioritization within your data governance framework.
Data Quality Assessment: Regular assessment of data quality is an ongoing and essential practice in data governance. It involves systematically evaluating data for accuracy, consistency, completeness, and reliability. Data quality assessments help identify and rectify inaccuracies, inconsistencies, or anomalies in your datasets. These assessments can be automated or manual and should be integrated into your data governance processes to maintain data reliability over time.
Data Documentation: Comprehensive data documentation is a fundamental aspect of data governance. It includes metadata, data lineage information, data dictionaries, and other documentation that provides context and understanding of your data assets. This documentation aids in data discovery, understanding data transformations, and ensuring data lineage transparency. It facilitates effective data governance by providing a foundation for data management and decision-making.
Data Security Measures: Protecting data from unauthorized access is paramount. Data governance should include robust security measures to safeguard sensitive data. These measures encompass various practices such as encryption, access controls, data masking, and regular security audits. Encryption ensures that data remains secure, even if unauthorized parties gain access to it. Access controls restrict data access based on user roles and permissions. Regular security audits and monitoring help detect and respond promptly to security threats.
Data Privacy Compliance: Data privacy regulations, such as GDPR, CCPA, or industry-specific laws, require organizations to protect individuals’ data privacy rights. Data governance must ensure that data handling practices align with these regulations. This involves understanding the specific requirements of applicable privacy laws, implementing necessary controls, and regularly reviewing and updating data privacy practices to remain compliant.
Data Lifecycle Management: Defining the lifecycle is critical for efficient data governance. This includes specifying how data is created, stored, used, and archived, or disposed of. Data governance practices should align with this lifecycle, ensuring that data is retained only as long as necessary and that data retention policies adhere to legal and compliance requirements. Effective data lifecycle management prevents data from becoming obsolete and reduces storage costs.
Data Governance Training: Building awareness and competence among employees regarding data governance policies and practices is essential. Providing training programs and resources helps employees understand their roles and responsibilities in maintaining data integrity. Data governance training ensures that all stakeholders are equipped to follow data governance guidelines and contributes to a culture of data responsibility within the organization.
Continuous Monitoring and Improvement: Data governance is not a one-time effort; it’s an ongoing process. Continuously monitor data governance practices to assess their effectiveness and adapt to changing data needs. Regular audits, reviews, and feedback mechanisms help identify areas for improvement. Organizations can refine their data governance initiatives by embracing a continuous improvement mindset to meet evolving business requirements and industry standards.
Incorporating these best practices into your data governance framework lays the foundation for effective data management, protection, and utilization. It ensures that data remains valuable and supports informed decision-making while mitigating risks and maintaining compliance with relevant regulations.
How do I begin implementing Data Governance from Zero to Hero?
In the modern data-driven landscape, establishing rudimentary data management practices to become a genuine data governance hero is both a strategic and evolutionary imperative. Organizations must embark on a systematic and comprehensive transformation to implement data governance effectively, especially from a “zero to hero” standpoint. This transformation is about safeguarding data and harnessing its full potential to drive innovation, informed decision-making, and organizational excellence. In this intricate journey, we will explore ten pivotal steps that, when diligently followed, can guide any organization from being data governance novices to true data governance champions.
The Foundation of Data Governance
At its core, data governance begins with a clear understanding of data’s strategic value. The first step is establishing a data governance framework, appointing roles and responsibilities encompassing Data Stewards, Data Owners, and Data Governance Committees. With these pillars, organizations can define their data strategy and objectives, ensuring that data aligns seamlessly with broader business goals. Data classification, an essential component, helps identify sensitive and critical data, laying the foundation for data protection measures.
The Implementation Process
The next phase involves developing and enforcing data governance policies and standards. This step encompasses creating data quality metrics, access controls, and data retention policies to ensure data is accurate, secure, and compliant with regulations. Collaboration across departments becomes paramount as Data Stewards collaborate with technical teams to implement data profiling, data lineage tracking, and data cleansing procedures. Data literacy programs educate employees on the significance of data and how to utilize it effectively. Simultaneously, organizations must invest in data governance technology, such as data cataloging and metadata management tools, to automate and streamline data management processes.
Continuous Improvement and Heroic Status
Becoming a true data governance hero requires a commitment to continuous improvement. Organizations should regularly assess the effectiveness of their data governance initiatives, conduct audits, and refine policies and practices as needed. Data governance should adapt to changing business landscapes and evolving data regulations. As data maturity grows, organizations can leverage advanced technologies like artificial intelligence and machine learning for predictive analytics and anomaly detection, ensuring data governance remains agile and robust. Ultimately, a data governance hero is an organization that not only safeguards its data but also leverages it to achieve remarkable feats of innovation, agility, and strategic success.
In conclusion, the journey from implementing data governance from zero to hero is a profound transformation that necessitates strategic planning, dedicated efforts, and an unwavering commitment to data excellence. The ten steps outlined in this exploration provide a comprehensive roadmap for organizations to transition from developing data management practices to the pinnacle of data governance. By embracing data as a strategic asset and fostering a culture of data-driven decision-making, organizations can protect their data and harness its transformative power to drive success in today’s data-centric world. Becoming a data governance hero is not a destination but a continuous journey of growth, adaptation, and innovation, ensuring that data remains at the heart of every strategic endeavor.
Data governance is not a one-size-fits-all solution.
Data governance is a tailored approach that aligns with an organization’s unique data landscape and goals. When done correctly, it ensures data remains a valuable asset rather than a liability. Following the best practices outlined in this guide, you can establish a robust data governance framework that maintains data integrity and supports informed decision-making.
Implementing these best practices may seem daunting, but the investment in data governance pays off through reliable, high-quality data that empowers your organization. If you have any questions or need further guidance on specific aspects of data governance, please feel free to reach out.