What does the CIA’s “estimation probability” have to do with data visualization and a Reddit poll?
Think of it like this: the CIA, and many government agencies, has teams who dig through research, write up reports, and pass them along to others who make the big calls. A big part of that process is putting numbers behind words, predicting how likely something is to happen, and framing it in plain language. Even the headlines they draft are shaped around those probability calls.
The reddit pole? Just an interested group of data people who decided to re-create this same study.
Did you know the CIA releases documents on a regular basis?
The CIA has a large resource catalog and we will grab from three different sources.
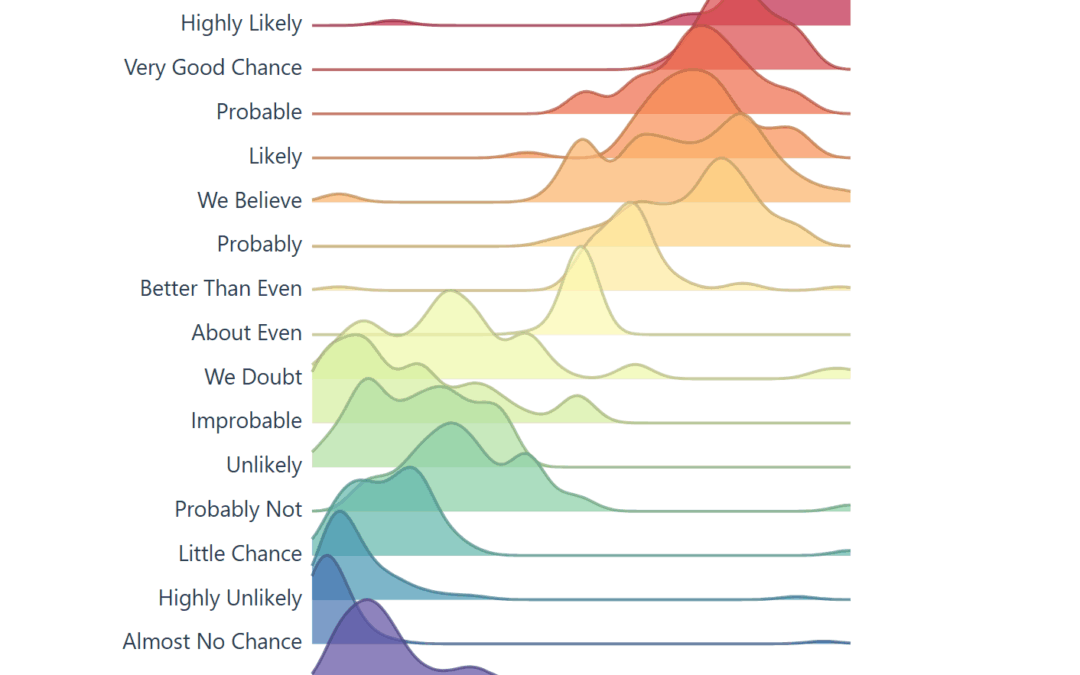
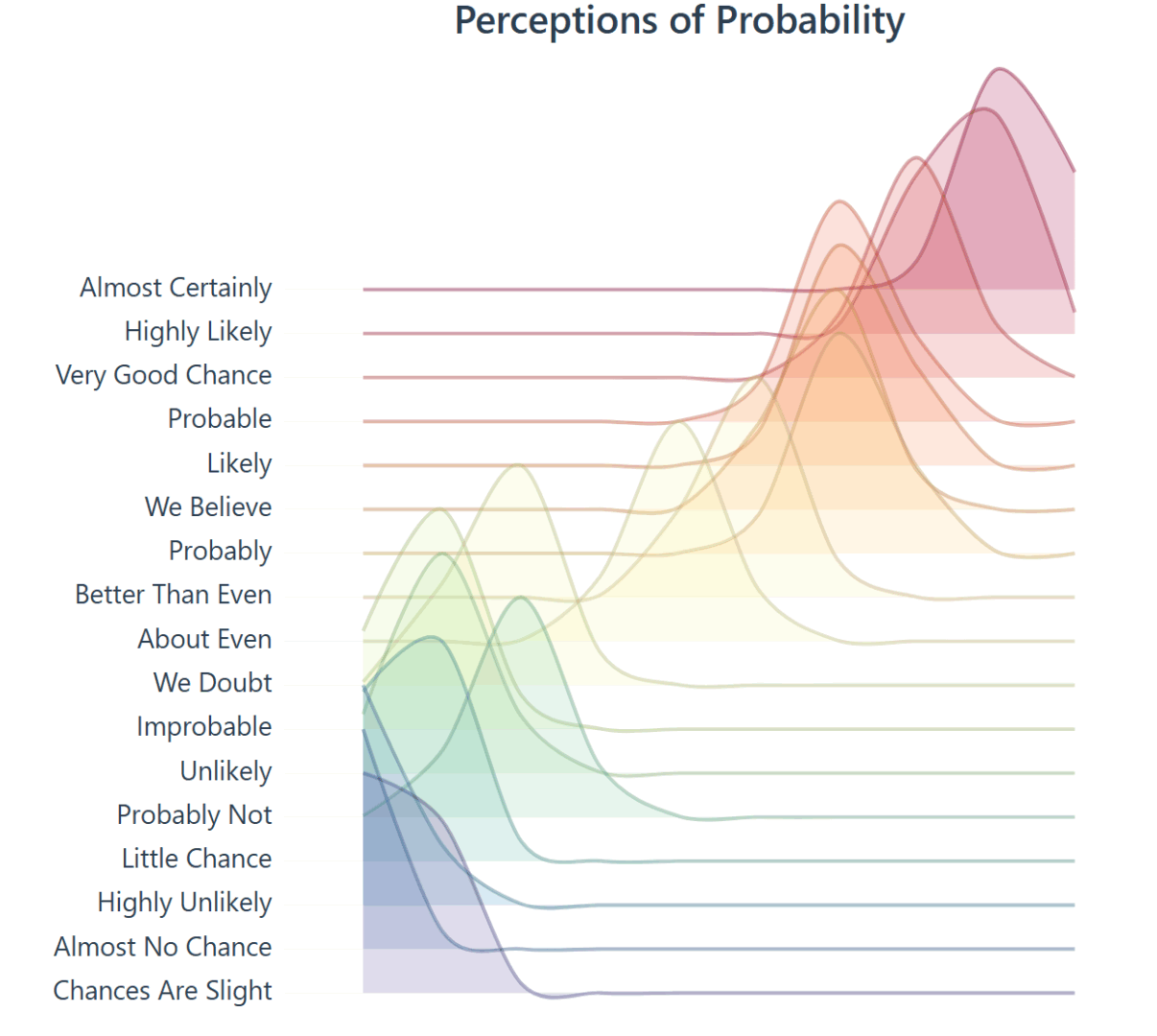
Lets explore the development and history of a ridgeline plot that shows the “Perceptions of Probability,” the curious world of data lovers, migrating data from CSV to JSON, building a visual using D3, dive into the complex history, and more.
Numbers behind the words.
The raw data in our D3 chart came from /r/samplesize responses to the following question: What [probability/number] would you assign to the phrase “[phrase]”? source.
Note: An online community created a data source that resembles the same study the CIA completed, using 23 NATO officials, more on this below. Below you will see images created to resemble the original study, and the background of the data.
Within the CIA, correlations are noticed – studied – quantified and then later released publicly.
In the 1950’s, the CIA noticed something happening internally and created a study.
Before writing this article I did not realize how much content the CIA has released. Like the studies in intelligence, fascinating information here.
Our goal is research the history behind ‘Perceptions of Probability,’ find & optimize the data using ETL, and improve on the solution to ensure it’s interactive, and re-usable. The vision is we will be using an interactive framework like d3, which means JavaScript, html, and CSS.
For research, we will keep everything surface level, and link to more information for further discovery.
The CIA studied and quantified their efforts, and we will be doing the same in this journey.
Adding Features to the Perceptions of Probability Visual
Today, the visual below is the muse (created by a user on reddit) and we are grateful they have this information available to play with on their github. They did the hard part, getting visibility on this visual and gathering the data points.
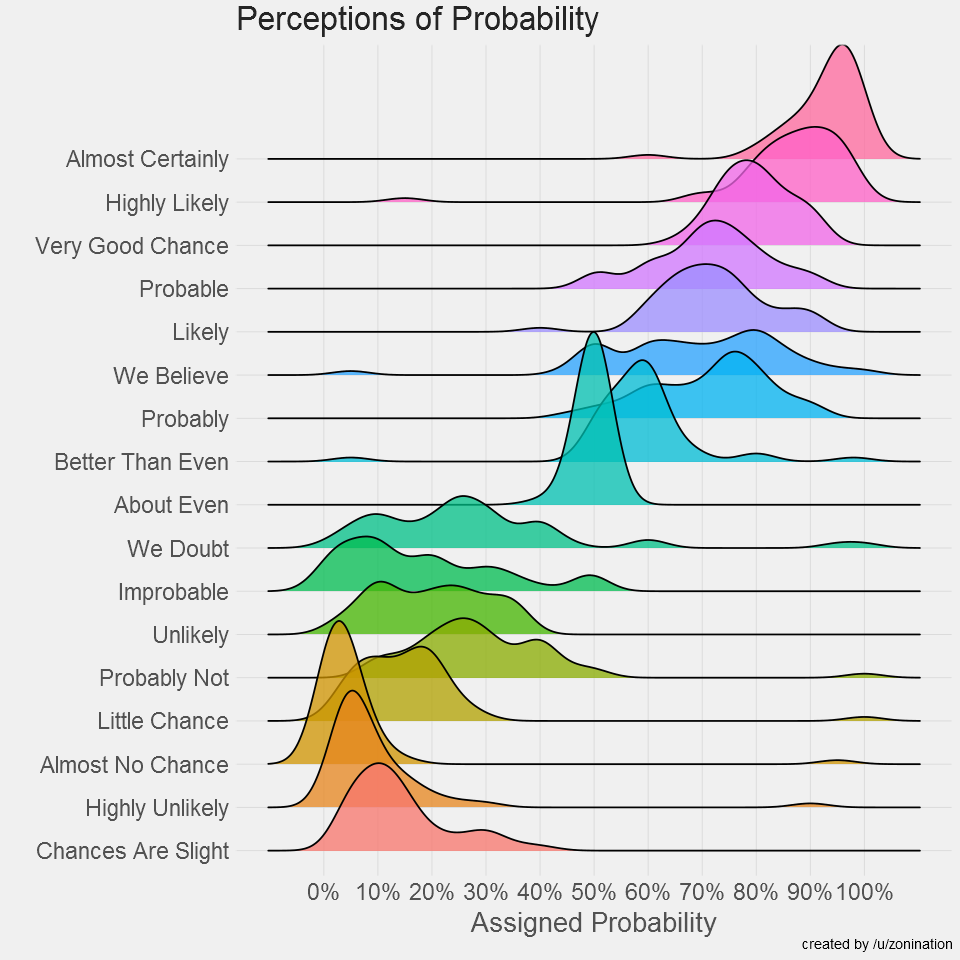
When you learn about the Perceptions of Probability, you’ll see it’s often a screenshot because the system behind the scenes creates images (ggjoy package). Alternatively that’s the usual medium online, sharing content that is static.
A screenshot isn’t dynamic, it’s static and it’s offline, we can’t interact with a screenshot, unless we recreate the screenshot, which would require the ability to understand R, install R, and run R.
This is limiting to average users, and we wonder, is it possible to remove this barrier?
If we looked at this amazing visualization as a solution we can improve and make more adoptable, how would we optimize?
What if it could run online and be interactive?
To modernize, we must optimize how end users interact with the tool; in this case a visualization, and we do our best to remove the current ‘offline’ limitation. Giving this a json data source also modernizes it.
The R code to create the Assigned probability solution above;
#Plot probability data
ggplot(probly,aes(variable,value))+
geom_boxplot(aes(fill=variable),alpha=.5)+
geom_jitter(aes(color=variable),size=3,alpha=.2)+
scale_y_continuous(breaks=seq(0,1,.1), labels=scales::percent)+
guides(fill=FALSE,color=FALSE)+
labs(title="Perceptions of Probability",
x="Phrase",
y="Assigned Probability",
caption="created by /u/zonination")+
coord_flip()+
z_theme()
ggsave("plot1.png", height=8, width=8, dpi=120, type="cairo-png")The code is used to manage the data, give it a jitter, and ultimately create a png file.
In our engineering of this solution, we want to create something that loads instantly, easy to use again, and resembles ridgelines from this famous assigned probability study. If we do this, it would enable future problem solvers another tool to solve, and then we are only 1 step away (10-30 lines of code) from making this solution accept a new data file.
The History on Estimative Probability
Sherman Kent’s declassified paper Words of Estimative Probability (released May 4, 2012) highlights an incident in estimation reports, “Probability of an Invasion of Yugoslavia in 1951.” A writeup on this was given to policy makers and their assumptions on what they read was a lower value than they had intended.
How long had this been going on? How often are policy makers and analysts not seeing the same understanding of a given situation? How often does this impact us negatively? Many questions come to mind.
There was possibly not enough emphasis on the text, or there was no such scoring system in place to explain the seriousness of a an attack. Even with the report suggesting there was a serious urgency, nothing happened. After some days past, in a conversation someone asked “what did you mean by “Serious Possibility?” What odds did you have in mind?
Sherman Kent, the first director of CIA’s Office of National Estimates, was one of the first to recognize problems of communication caused by imprecise statements of uncertainty. Unfortunately, several decades after Kent was first jolted by how policymakers interpreted the term “serious possibility” in a national estimate, this miscommunication between analysts and policymakers, and between analysts, is still a common occurrence.
Through his studies he created the following chart, which is later used in another visualization, and it enables a viewer to see how this study is similar to the study created here. Used in a scatter plot below this screenshot.

What is Estimation Probability?
Words of estimative probability are terms used by intelligence analysts in the production of analytic reports to convey the likelihood of a future event occurring.
Outside of the intelligence world, human behavior is expected to be somewhat similar, which says a lot about headlines in todays news and content aggregators. One can assume journalists live by these numbers.
Text has the nature to be ambiguous.
When text is ambiguous, I like to lean on data visualization.
To further the research, “23 NATO military officers accustomed to reading intelligence reports [gathered]. They were given a number of sentences such as: “It is highly unlikely that..” All the sentences were the same except that the verbal expressions of probability changed. The officers were asked what percentage probability they would attribute to each statement if they read it in an intelligence report. Each dot in the table represents one officer’s probability assignment.” This quote is from the Psychology of Intelligence Analysis.pdf, Richards J. Heuer, Jr.
The above chart was then overlayed on this scatter plot, of the 23 NATO officers assigning values to the text. Essentially estimating likely hood an event will occur.

Modernizing the Perceptions of Probability
Over time people see data and want to create art. My artwork will be creating a tool that can be shared online, interactive, and open the door to a different audience.
Based on empirical observations in data visualization consulting engagement, you can expect getting access to data to take more time, and for the data to be dirty. Luckily this data was readily available and only required some formatting.
The data was found here on github, which is a good sample for what we are trying to create. The current state of the data is not prepared yet to create a D3 chart. This ridgeline plot chart will require JSON.
Lets convert CSV to JSON using the following python:
import pandas as pd
import json
from io import StringIO
csv_data = """Almost Certainly,Highly Likely,Very Good Chance,Probable,Likely,Probably,We Believe,Better Than Even,About Even,We Doubt,Improbable,Unlikely,Probably Not,Little Chance,Almost No Chance,Highly Unlikely,Chances Are Slight
95,80,85,75,66,75,66,55,50,40,20,30,15,20,5,25,25
95,75,75,51,75,51,51,51,50,20,49,25,49,5,5,10,5
95,85,85,70,75,70,80,60,50,30,10,25,25,20,1,5,15
95,85,85,70,75,70,80,60,50,30,10,25,25,20,1,5,15
98,95,80,70,70,75,65,60,50,10,50,5,20,5,1,2,10
95,99,85,90,75,75,80,65,50,7,15,8,15,5,1,3,20
85,95,65,80,40,45,80,60,45,45,35,20,40,20,10,20,30
""" # paste your full CSV here
# Load CSV
df = pd.read_csv(StringIO(csv_data))
# Melt to long format
df_long = df.melt(var_name="name", value_name="y")
df_long["x"] = df_long.groupby("name").cumcount() * 10 # create x from row index
# Group by category for D3
output = []
for name, group in df_long.groupby("name"):
values = group[["x", "y"]].to_dict(orient="records")
output.append({"name": name, "values": values})
# Save JSON
with open("joyplot_data.json", "w") as f:
json.dump(output, f, indent=2)
print("✅ Data prepared for joyplot and saved to joyplot_data.json")With data clean, we are a few steps closer to building a visual.
Using code from a ridgeline plot, I created this density generator for the ridgeline to show density. This enables us to look at dense data, and plot it across the axis.
// Improved KDE-based density generator for joyplots
function createDensityData(ridge) {
// Extract the raw probability values for this phrase
const values = ridge.values.map(d => d.y);
// Define x-scale (probability axis: 0–100)
const x = d3.scaleLinear().domain([0, 100]).ticks(100);
// Bandwidth controls the "smoothness" of the density
const bandwidth = 4.5;
// Gaussian kernel function
function kernel(u) {
return Math.exp(-1 * u * u) / Math.sqrt(2 * Math.PI);
}
// Kernel density estimator
function kde(kernel, X, sample, bandwidth) {
return X.map(x => {
let sum = 0;
for (let i = 0; i < sample.length; i++) {
sum += kernel((x - sample[i]) / bandwidth);
}
return { x: x, y: sum / (sample.length * bandwidth) };
});
}
return kde(kernel, x, values, bandwidth);
}This ridgeline now closely resembles the initial CIA tooling rebuilt by the github user.
We have successfully created a way to create density, ridgelines, and in a space that can be fully interactive.
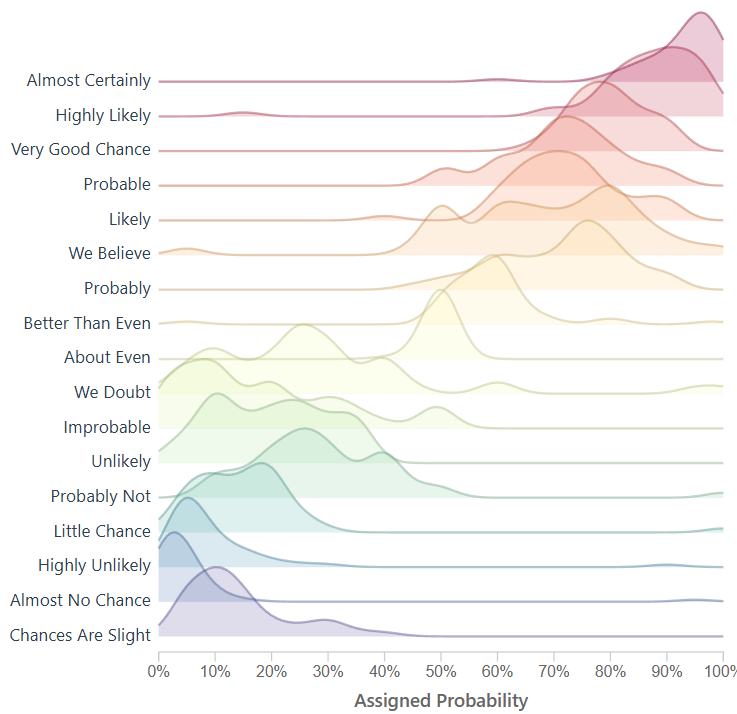
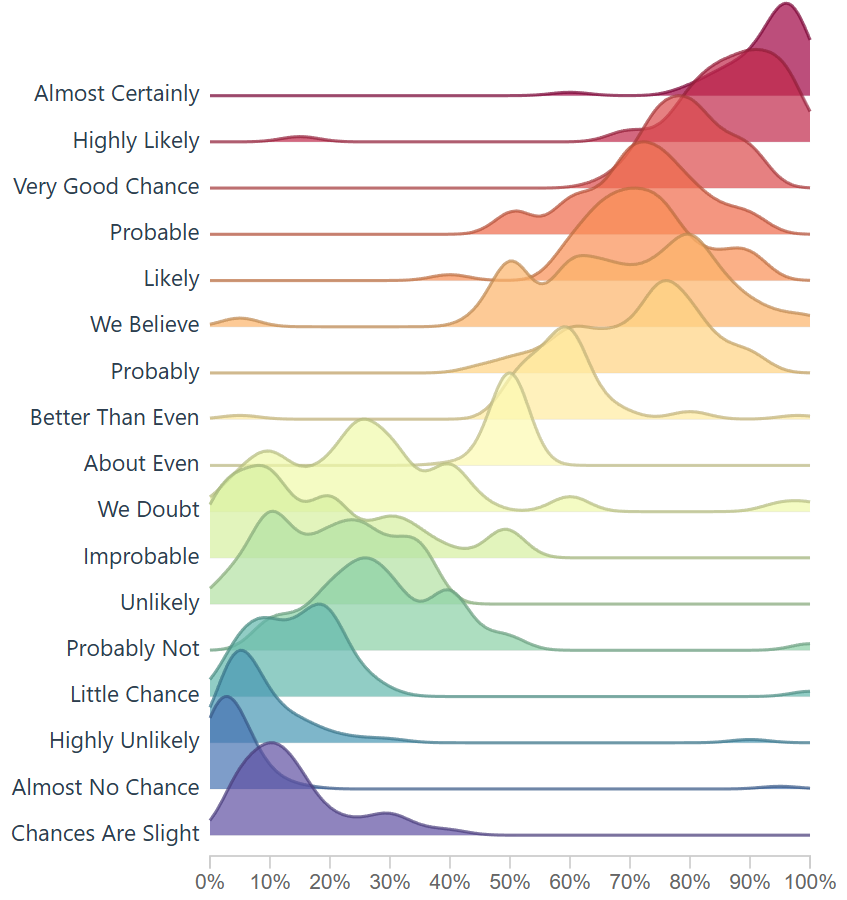
Not every attempt was a success: here’s an index based version. Code below. This method simply creates a bell-shape around the most dense area, which does enable a ridgeline plot.
// Create proper density data from the probability assignments
function createDensityData(ridge) {
// The data represents probability assignments, we need to create a density distribution
// around the mean probability value for each phrase
// Calculate mean probability for this phrase
const meanProb = d3.mean(ridge.values, d => d.y);
const stdDev = 15; // Reasonable standard deviation for probability perceptions
// Generate density curve points
// Density Generation Resolution
const densityPoints = [];
for (let x = 10; x <= 100; x += 10) {
// Normal distribution density
const density = Math.exp(-3 * Math.pow((x - meanProb) / stdDev, 2));
densityPoints.push({ x: x, y: density });
}
return densityPoints;
}There’s a bit of fun you can have with the smoothing of the curve on the area and line. However I opted for the first approach listed above because it gave more granularity and allowed the chart to sync up more with the R version.
This density bell shape curve producer could be nice for digging into the weeds and cutting out potential density around the sides, in my opinion it didn’t tell the full story, but wanted to report back as this extra area where we adjust the curve was fun to toy with and even breaking the visual was pleasant.
// Create smooth area
const area = d3.area()
.x(d => xScale(d.x))
.y0(ridgeHeight)
.y1(d => ridgeHeight - yScale(d.y))
.curve(d3.curveCardinal.tension(.1));
const line = d3.line()
.x(d => xScale(d.x))
.y(d => ridgeHeight - yScale(d.y))
.curve(d3.curveCardinal.tension(.1)); Thanks for visiting. Stay tuned and we will be releasing these ridgelines. Updates to follow.
This solution was created while battle testing our ridgeline plot tooling on Ch4rts. Tyler Garrett completed the research.























