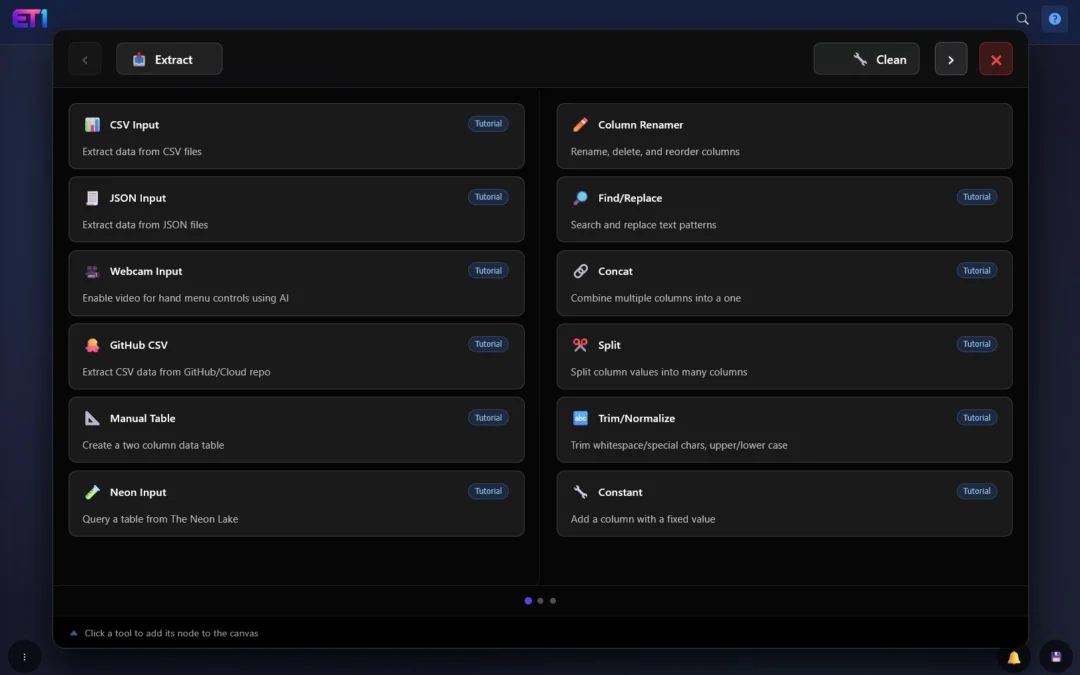
We have overhauled our original menu in ET1.1 to improve the adoption of the software and ease of usage.
We’ve completely redesigned the node menu to now be a source of knowledge. The Training Menu in ET1 makes learning about data transformation tools faster, attaches to the training built into dev3lop, and is more intuitive for smaller devices. The mobile device is not a common place for ETL/Analytics! Yet, with et1.1 it’s seamless.
What We Fixed
The original menu needed a major update, simply does not work on mobile, smaller devices was a struggle, and it’s the only source of information per node in the software. We are eager to expand.
Tool Descriptions That Actually Show Up
The biggest issue? Tool descriptions weren’t visible in the dual comparison view. You’d see tool names but no explanation of what they did. We fixed this by properly displaying descriptions under every tool card, so you can quickly understand what each node does without clicking around.
Say Goodbye to Cramped Layouts
Nobody likes reading text that’s squished together. We added subtle spacing throughout the menu—just enough breathing room to make everything feel polished without wasting screen space. Cards now have consistent padding, clean margins, and text that wraps naturally within its container.
Scrolling Instead of Squishing
When you have a lot of tools to browse, the old menu would try to cram everything into view by compressing cards. Now, each panel scrolls independently while maintaining proper card sizing. No more squeezed content—just smooth, natural scrolling.
What We Added | In-App Tutorials
The biggest new feature: tutorial buttons. Over 19 different tools now have a small “Tutorial” pill next to their name. Click it, and a clean overlay opens right inside the app with documentation, examples, and tips. No need to leave your workflow or open a new tab.
The footer tips now clearly explain how to use the menu:
Click any category to view tools with descriptions
Drag tools onto the canvas to create workflows
Use left/right arrows to browse categories in dual view
Click a tool to add its node to the canvas
Technical Improvements You’ll Notice
No More Ghost Clicks
We fixed a frustrating bug where clicking in empty space after closing the menu would still trigger node creation. The menu is now fully non-interactive when closed—no phantom clicks, no accidental nodes.
Responsive Design That Works
The dual comparison layout now kicks in at 700px instead of 1200px, giving tablet users the same side-by-side view. We also eliminated redundant CSS that was causing weird behavior at certain screen sizes.
Cleaner, Faster
By streamlining the responsive breakpoints and removing duplicate code, the menu loads faster and behaves more predictably across all devices.
Why This Matters
Learning a new tool shouldn’t require a manual or external documentation hunt. With these updates, you can:
Explore faster — See descriptions and tutorials without leaving the app
Learn in context — Read about a tool right before you use it
Work efficiently — No more squished layouts or confusing navigation
Try It Out
Open the help menu (ℹ️ icon in the toolbar) and explore the dual comparison view. Click any “Tutorial” button to see the in-app documentation system in action.
We think you’ll notice the difference immediately—cleaner layout, better spacing, and instant access to learning resources right where you need them.
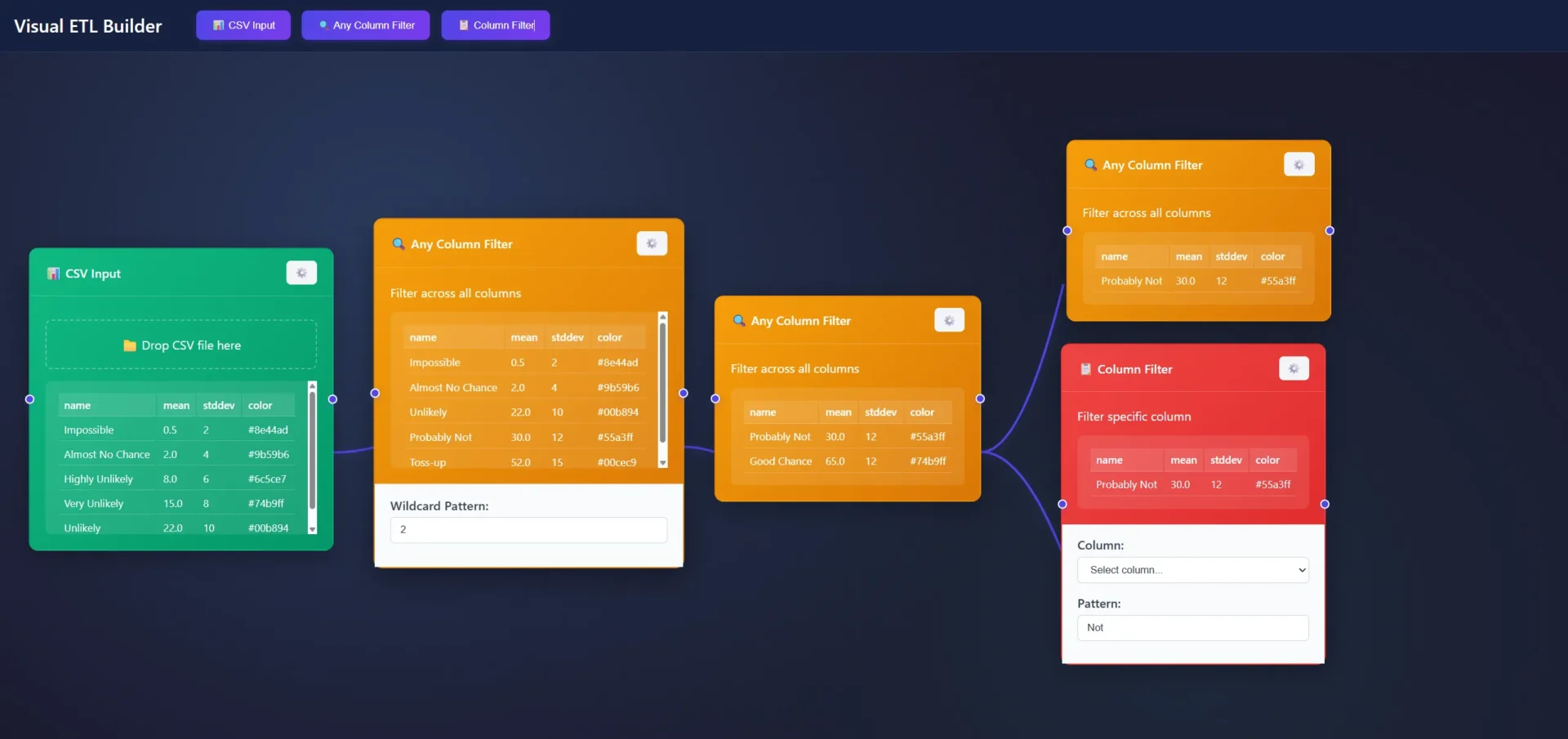
Sneak Peek: Live Demo
Here’s what the new dual comparison layout looks like in action. Notice the clean spacing, visible descriptions, and tutorial pills on each tool:
Each change log I will share an assortment of changes, plus information on the history, firsts, major updates, the change log, and most importantly accessibility improvements.
Accessibility – Using emerging tech to improve user experiences.
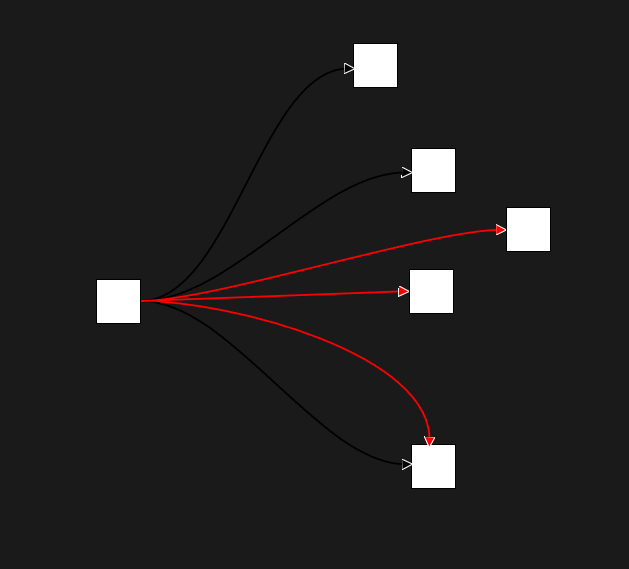
Mouse hovering and highlights enable cells/rows/column highlighting. Plus, as a node does something, those columns are highlighted. These are two important element to helping people avoid distractions and we will continue to add features like this in the future.
Improving visibility, Major Design Update
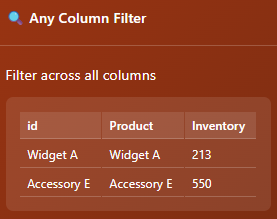
There are many nodes in ET1 that are hard to see when computer monitors are in dark mode, so we have remediated this across all of these known nodes. Like below screenshot, Any Column Filter was nearly impossible to read in dark mode. This has been remediated in ET1.1 Neon, these nodes are now darker.
Today, it’s darker. Many nodes are fixed in this design update.
Google Edge AI for Accessibility
Webcam enabled and hand monitoring software has been crafted to enable users who do not want or have a mouse/keyboard. We hope this demonstrates to other companies that creating multiplayer software is more about using imagination and your brain, rather than being stuck on the keyboard and mouse plane of thought.
While your hand menu is open, someone else can click the buttons with a mouse!
Ergonomic win
Lets face it, being on a computer constantly is bad for your back, shoulders, neck starts to hurt, arms and fingers eventually get worse. With ET1, we wanted to remove you from the “fixed computer position” enabling users to present data as a solution by modeling the solution with their fingers.
The only ETL / data visualization software provider that is using Google Edge AI to improve accessibility.
Increasing adoption
Striving to make ET1 more user friendly for people in AR, VR, and avoiding getting too technical.
This will open the audience for ET1 beyond ETL and data visualization professionals.
Building Webcam navigation and development capabilities has improved the fun factor when explaining how data works to younger generations <12 years of age, and I encourage you to give it a shot if your children are showing interest. This has become a great educational device.
Improving the ease of usage
Making the software easy to use is important and we have spent a great deal of time improving the UX in a minimal way so that it continues to remain easy to understand.
Added a menu just for learning.
At the top right, you will find a question button. This opens an expandable learning menu that helps people understand more about the nodes they are using. As this gets more comfortable we have more advanced menus under hood. But until you’re comfortable, this is the menu to use.
Added a search bar.
This will open the pro left side menu and allow you to begin to type and find nodes you’re looking to utilize, and reduces the selection of nodes based on the search. This is a big move towards a more mobile friendly ET1 solution.
Added a pro left side menu.
Click the logo and the left side menu opens. These nodes can be clicked to select the node, however the power here is dragging and dropping the nodes and this then automatically connects to any nodes on your canvas based on proximity!
History and background
From a drawing on paper when we founded DEV3LOPCOM, LLC, to a software with a login.
The early stages, it was more about understanding how to reverse engineer figjam because lets face it that application is amazing.
To transitioning to data flowing through a DAG, and aiming to perfect three nodes. Not completely convinced on a “name” for the application I opted for visual ETL builder.
I love this older version, the connections aren’t connecting the the circles and it appears as if the application is sad or happy. Was a funny mistake.
Also, before this application, it was an even more simple tool, a simple csv opening application that created a data grid.
This data grid also had a wildcard filter which felt pretty exciting at the time, but I wanted the application to act more like alteryx/knime with that futuristic vibe of enso.
Upsert – our favorite feature in postgresql is upsert because it enables a cleaner code base around updates and inserts, very user friendly for full-stack engineers, great for webhooks, but not user friendly for average data users. This tool makes it easy!
Append – Logging? Monitoring? Tracking everything over and over? This is the way to to do it. If you’re trying to track what is happening to a file or system, append is a great way to manage your data.
Overwrite – This will delete the data in that table, then overwrite it with whatever you pipe down stream to this node. Very powerful, likely what most people need, however could be very detrimental without the right understanding. We dive deeper here on Neon Output Node training.
Here’s a quick run down of the latest sprints:
2025-09-30 18:04 CT —
Implemented Phase 1 (display disambiguation) and Phase 2 (per-user unique lake_name) for Neon Lake
Notes: Badges for rows/created/updated/internal; related workflows show OW and removed with tooltips; GET returns created_at; visibility includes c.user_id.
Notes: Added ensureUserFromAuth (reconcile by external_id, fallback email); sessions now use canonical external_id in sub and include uid claim. Workflows uses helper to avoid duplicate users.
2025-10-12 00:22 CT —
Remove Stack Auth redirects
Files: netlify.toml
Notes: Deleted legacy /handler/* redirects that pointed to Stack Auth; app uses GitHub Direct exclusively.
Notes: Migration detects duplicates first and returns 409 with details until dedupe is applied; dedupe-users supports dry-run and apply with transactional FK repoints (workflows, data_cache).
2025-10-12 00:25 CT —
Fix Neon Lake UUID error with external_id sessions
Files: netlify/functions/neon-lake.js
Notes: Resolve user by external_id first; only treat sub as UUID when it matches regex. Fixes “invalid input syntax for type uuid: ‘github:…'”.
Notes: Added 🚢 Ship button next to table input (for new table creation only, keeps clickable and spins). Suggestions only show on focus and hide on blur; row counts in suggestions now use backend total.
Notes: Row totals now detect nested shapes (rows: [{rows:[…] }] and rows: {rows:[…]}) using CASE expressions; totals returned as ‘total’ without inflating payload.
2025-10-12 13:26 CT —
Neon Lake queries simplified and indexed path ready
Files: netlify/functions/neon-lake.js
Notes: Resolve userId once via ensureUserFromAuth; replace broad OR predicates with direct (c.user_id = userId OR u.id = userId). Ready to drop the OR after backfilling c.user_id.
Notes: preserveDuplicates true only in Append; Upsert/Overwrite do not preserve. Keeps preview/save behavior consistent.
2025-10-13 09:50 CT —
Add created_at/updated_at across all write modes (save path)
Files: node/settings/neon_output.js
Notes: Append sets both timestamps for new rows; Upsert preserves created_at and stamps updated_at; Overwrite stamps updated_at for all and backfills created_at when missing.
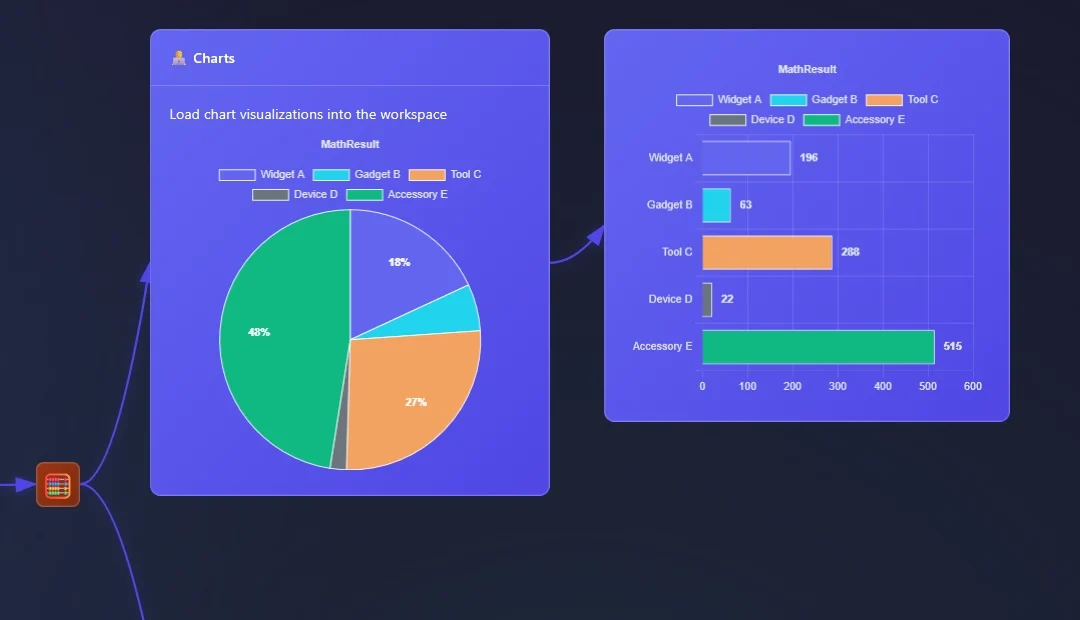
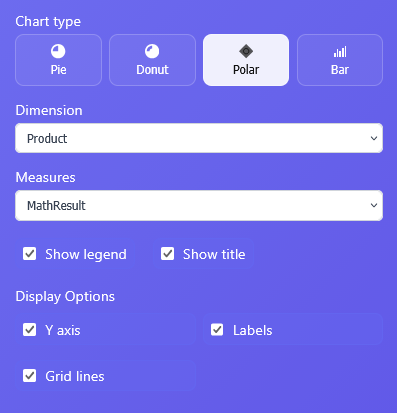
In ET1.1 Neon you can now pipeline your data to Charts.
Pie Chart
Donut Chart
Polar Chart
Bar Chart
This covers an array of classic data visualizations and the same highlighting functionally flows through from data grid to charts. Making it the first ETL software that help you see and understand your data between tools.
Using graph tech, we can show you up and downstream what is happening by mousing over and highlighting in the software.
These data visualizations are “single measure” and “single dimensions” charts.
Charts Node will automatically infer a good dimension and measure based on what you’re sending to the node. Also, manual selections are good for directing the tool the right direction.
Data can continue to pass through the charts.
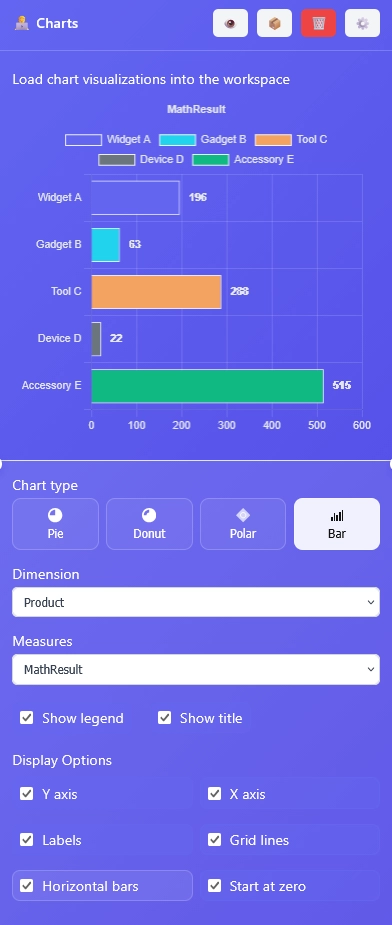
Charts Node: Bar Chart
Creating a bar chart in ET1.1 is possible and has the most settings currently. However in the spirit keeping everything very simple and user friendly for the future of AR/VR users, we want to reduce whatever settings possible and each Chart Type selection will hide “features” related to that chart type, which we are going to term “display options” for the foreseeable future.
Here’s the bar chart features aka Display Options:
Y axis
X axis
Labels
Grid Lines
Horizontal Bars
Start at zero
Display options are change as Chart Types change.
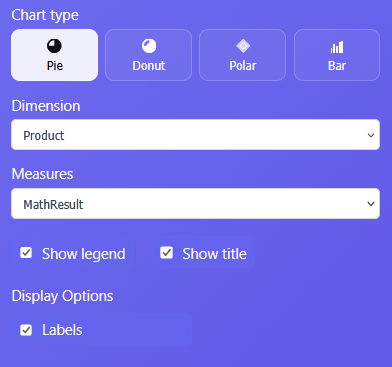
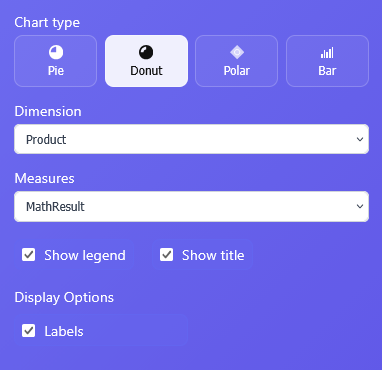
Pie Charts and Donut Charts in ET1 Charts Node
Pie charts and donut chart are similar.
Polar Chart in ET1 Charts Node
Seeking a no-code way to create chartjs Polar charts? Look no further, we built that app here!
Also, learn about how we are the first ETL/Visualization company to deploy Google Ai Edge technology in ET1.1, so that you can use your fingers/hand to solve problems, which turns this into a multiplayer solution!
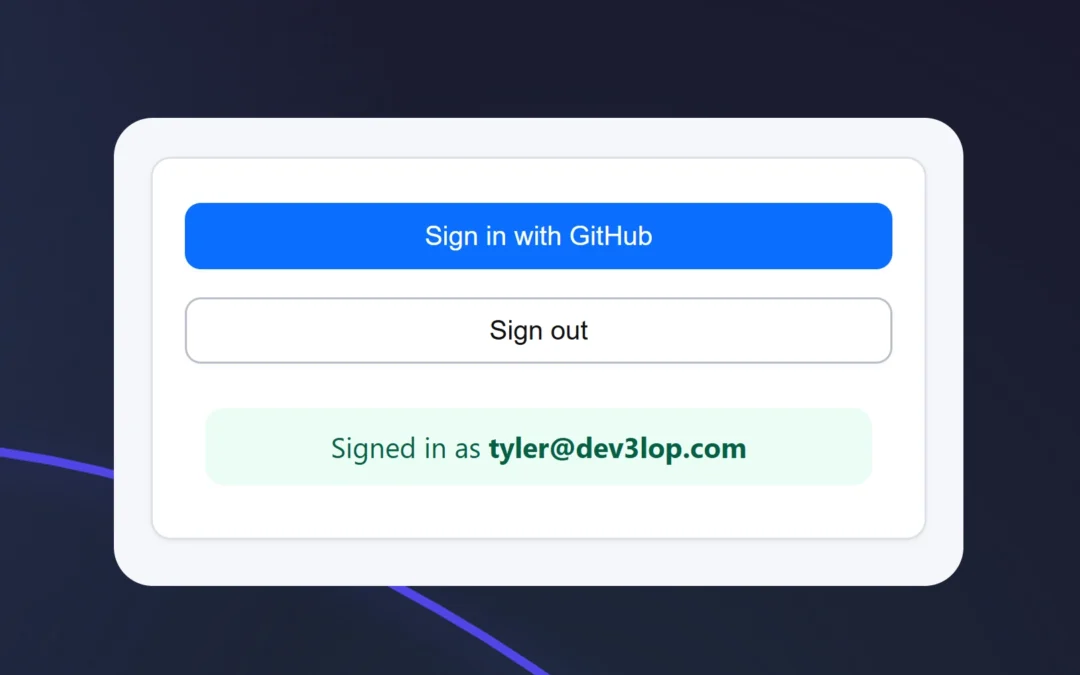
We are excited to announce the GitHub OAuth Login page is now active in ET1.1 (Neon).
Picture a world where your most sensitive data files and database tables are protected with the same robust security protocols and layers you’d expect from a leading, Fortune 500 corporation.
Without having to setup data security; login, authorization, storage, persistence, managing login information and keeping data compliance people happy.
In ET1.1, we encourage end users to begin translating important data to solutions that can become a single source of truth around their team, organization, or across the sea.
Authorization isn’t just a checkbox on our to-do list
Authorization, it’s our top priority, and that’s why we went with GitHub’s OAuth!
Our commitment with developing solutions is to cultivate and maintain an exceptionally secure environment, safeguarding both our users and the valuable data they entrust to us.
With this completed we are actively seeking people to participate in beta testing.
ET1 is using Auth2 through GitHub, providing two-factor authentication to end-users of ET1.
FYI; Using dozens of SaaS products during analytics consulting engagements is our skill, building open source solutions from scratch is our specialty, and…
At DEV3LOPCOM, LLC, we have a decade+ of experience beta-testing and deploying numerous authentication tools in advanced production settings (enterprise and GOV). With this solution, I have developed a unique perspective on streamlined login/security and optimized our ET1’s login process.
ps… If you need assistance with Auth2 in your software, let me know
– Tyler Garrett, Founder tyler@dev3lop.com..
About Authorization
Software authorization is the process of determining what an authenticated user is permitted to do within a software system, such as accessing specific files, performing actions, or using certain features. It is crucial for ensuring security by preventing unauthorized access to sensitive data and functionality, and for maintaining operational control by managing user permissions, tracking usage, and enabling personalized user experiences that enhance customer satisfaction and loyalty.
About GitHubs OAuth (Auth2)
We did not create auth2, rather we are utilizing auth2! Think of Auth2 like a way to keep your sensitive information safe and secure, we don’t store your password.
This helps you login fast, seamlessly, if you’re already logged into GitHub in another tab – it’s a 1 click login – and this process keeps your solution/data safe.
What is Auth2?
Auth2 is a protective layer we use to help use generate data security per user.
Auth2 is an industry standard when it comes to managing data privacy and security.
People are going to want to add their data into ET1, different kinds of data, and we are working hard to ensure this is not only possible but also the safest it can be. We will not need to recreate the wheel, but instead utilize vetted systems. This enables us to offer hippa compliant storage, soc2 compliant storage, and way more… Without over complicating the UX.
With ET1, we are going a similar direction as our cronjob software Canopys Task Scheduler, and using different under hood tech. Excited to share, founder of dev3lop, Tyler Garrett, created the entire authorization flow. The Login to ET1 with GitHub Authentication is now live for beta testing!
Setting up 2 way auth is VIA GitHub is easier than you think so here’s a link to GitHub Auth Documentation and more importantly it unlocks Google emails. Plus, we like the idea of advocating for a software we love to use.
If you don’t have a GitHub account, please create one
If you have a github account, login
We only request your ’email’, we don’t save your password.
Github Auth and User Data Explained
Here’s a simple, privacy‑first explainer of the users table, plus a short technical brief of “GitHub Auth” for the curious.
Users table (what each column means) Source:
database-schema.sql → table users
id (UUID)
A random unique tag the system gives you when you first show up.
It’s not your email or username.
Think of it like a sticker on a package so it can be tracked without opening it. 🔒
external_id (text)
A number/string that represents you from GitHub.
It’s how the system knows “the same person” across sessions without storing a password here.
Marked unique, so there’s only one of you. ✅
email (text, optional)
Used for “who’s signed in” display or contact. ✉️
created_at (timestamp)
When your record was first created.
Like a “birthday” for your account in this system. 🗓️
updated_at (timestamp)
When anything about your record last changed.
Auto‑updated so there’s an honest trail. 🕒
Why this is privacy‑friendly
Minimal data: just an internal id, a GitHub id, and optionally an email.
No passwords stored here. Authentication happens through GitHub, so this table isn’t a vault of secrets.
Clear timestamps help you audit “when did this get created/updated?”
Short technical brief: GitHub Direct (for the nerds)
Flow: Browser requests GitHub OAuth → user consents at GitHub → GitHub redirects back with a code → the backend exchanges code for tokens → identity is read (e.g., user id, email) → app creates/updates users using external_id as the stable key.
Why we use “Direct” conversations with GitHub? It talks straight to GitHub’s OAuth endpoints, avoiding extra middle SaaS style layers that can fail, require passwords, and become a single point of failure.
Data model: external_id is the anchor. Email is optional data that may change; external_id won’t.
Security posture: No passwords stored locally. Use HTTPS, strict redirect URIs, and least scopes (often user:email). Tokens should be short‑lived and stored server‑side with care.
To keep your account secure, you must authenticate before you can access certain resources. When you authenticate, you supply or confirm credentials that are unique to you to prove that you are exactly who you declare to be.*
TL;DR tech stuff
You get a private internal id, a “GitHub id”
so the system recognizes you, and an email.
No password stored here, that would not be safe!
GitHub Auth = clean OAuth (Auth2) with GitHub as the identity source.
Plus GitHub includes a simple Google Login which is very secure and our preference.
Our history with authorization
Previous software we released, Canopys Task Scheduler, a desktop task schedule for both windows and mac, was a good demonstration of our knowledge with desktop development, creating executable files, and authorization embedded into an electronjs desktop only application. Building native web applications on desktop, using Auth0s authorization, a local SQLite database, not an easy task, however with NodeJS and electronjs we think life is much easier.
Learn more about ET1, contact us for any questions, demo, and access to beta.
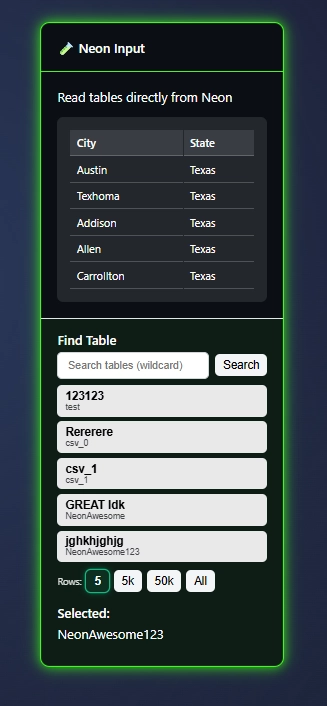
The Neon Input Node is our first managed database access node, and an intuitive approach to giving people access to a serverless PostgreSQL which users are able to manage in Neon Lake.
Data here is safe, and protected by 0Auth (Two way authentication).
As you use ET1.1 csv files, json, and manual tables, this data will automatically flow to the Neon Lake. Making it available, immediately, in the Neon Input Node.
Think of the Neon Input Node as a way to collaborate easier across data development, and a way to begin bringing together flat files lost in the organization – in one node.
The Neon Input lets you access the Neon Lake from any Workflow.
Neon Input Node, enables teams to work together on the same source of truth and helps you to work across workflows with the same data source.
ET1 Neon Input Node requirements
ET1 Neon Input Node is not available in the Bronze Edition of ET1.