In an era where data fuels innovation, companies stand or fall by how effectively they manage their data assets. While most enterprises acknowledge the importance of securing primary datasets, fewer pay enough attention to derived data—the enriched, transformed, and processed versions that often power advanced analytics, customer insights, and strategic decisions. Proper rights management for these derived data assets ensures regulatory compliance, promotes collaboration, and mitigates risks of misuse or unintended exposure. By laying down the foundation of smart practices and robust frameworks for managing derived data’s intellectual property and access rights, organizations can unlock greater agility, foster innovation, and confidently harness their data landscape’s full potential.
Understanding Derived Data: The New Frontier of Data Rights Management
Data teams worldwide generate immense amounts of derived data each day, including enhanced analytics outputs, complex predictive models, and sophisticated visualizations. Made from base datasets, derived data assets often represent proprietary insights and competitive advantages crucial to organizational innovation and growth. However, companies frequently overlook these datasets when discussing data governance and security. Derived data is particularly susceptible to rights mismanagement due to its indirect origin and ambiguous lineage. By not explicitly defining ownership, usage rights, and access controls, organizations could unknowingly expose themselves to regulatory scrutiny and unanticipated liabilities.
Consider credit scoring models in financial institutions, built from customer transaction databases. While securing customer transaction data is standard practice, how many companies diligently articulate proprietary usage rules around the derived credit scoring algorithms? Similarly, geospatial visualizations like the ones produced using advanced cartogram implementations often include layers of public and private data. If ownership stakes and usage permissions aren’t clearly delineated, these visualizations risk unauthorized redistribution, intellectual property disputes, or competitive harm. In short, derived data demands the same rigorous rights management practices as foundational datasets—if not more.
The Risks of Ignoring Derived Data Rights Management
The rapid proliferation of data analytics practices, from traditional business intelligence reports to innovative AI models, has caused derived data assets to multiply exponentially. Without clear systems in place to handle rights around these data derivatives, organizations face mounting risks. The most immediate threat is compliance. Regulatory standards, such as GDPR or CCPA, mandate precise tracking of customer data usage and derived analytics. Neglecting derived data rights management leaves companies vulnerable to infringements, fines, and reputational damage.
Another risk factor involves intellectual property—valuable analytic structures or proprietary visualizations can be lost, mishandled, or misappropriated without proper oversight. Take advanced distributional analyses represented through visual analytics techniques like violin plot implementations. Without clearly assigned rights, these analytical insights could leak into public domains or competitive organizations, diluting competitive differentiation and wasting research and development investments. Weak controls and ambiguous ownership models hamper collaborations too, making it difficult to share data across teams, geographies, and partner ecosystems safely and smoothly.
Finally, without explicit governance policies, derived data creates opportunities for misuse, either through intentional exploitation or unintended mishandling. Organizations must prioritize rights management controls for all data, ensuring stakeholders clearly understand their roles, responsibilities, and restrictions around data derivatives.
Implementing Robust Derived Data Rights Management Practices
No organization gets rights management right overnight; it’s a structured, continuous process requiring coordination, planning, and governance oversight. First and foremost, organizations should establish clear data governance structures that explicitly recognize derived data rights management. Data governance councils should ensure alignment among business, legal, and technical stakeholders, providing vision, guidance, and accountability as rights policies evolve across the enterprise.
Developing detailed data lineage maps can also mitigate derived data risks. Data lineage tracking can effectively document the transformation processes data undergoes from initial ingest to analytical consumption. Companies leading in modern data architectures utilize sophisticated cloud-based data frameworks—such as the ones described in discussions around data lakehouse implementations—to intelligently capture transformation metadata. Robust metadata registries and catalogs help organizations determine derived data ownership, simplify auditing, access management, and remediate issues proactively.
Implementing technology frameworks with effective rights management features is essential. For structured asset protection, leveraging role-based access controls (RBAC) specifically adjusted for analytic environments ensures the correct stakeholders with proper authorization access derived data assets. Technologies like Microsoft SQL Server significantly streamline managing, securing, and governing complex data environments, making partnering with Microsoft SQL Server consulting experts invaluable for optimizing data rights implementation.
Leveraging Automation and Parameterized Pipelines for Enhanced Control
Automation plays a pivotal role in securing derived data in dynamic, fast-paced enterprise environments. Automated tagging and metadata management ensure derived data rights and usage information consistently flow alongside analytic outcomes, reducing manual interventions and minimizing errors or omissions. Smart processes leveraging parameter-driven pipeline automation—such as those described in informative content about parameterized pipeline templates—allow standardized and scalable data processing procedures to embed information on rights management automatically.
Parameterized pipelines provide extensive flexibility, making it easier for data engineers and analysts to generate deterministic, secured data products aligned with established regulatory standards. With automated predefined governance rules embedded in these processes, organizations significantly limit regulatory breaches or unauthorized data usage, thereby ensuring compliance.
Automation further empowers report creators, dashboard developers, and analysts to innovate safely. For example, insightful customer-focused analytics like the customer lifetime value (CLV) analyses can offer tremendous market insights. Yet, without automated rights management tagging embedded in the analytic pipeline, these insights can unintentionally expose sensitive customer data beyond intended teams. Robust automated controls combined with intelligent pipeline templates ensure derived data asset governance comprehensively, consistently applied, and securely maintained throughout the analytic lifecycle.
The Competitive Advantage of Strong Derived Data Rights Management
While strong data protection and governance are frequently seen strictly through the lenses of risk mitigation, derived data rights management also carries tremendous strategic value. Enterprises excelling in managing derived data rights not only improve compliance posture but position themselves to confidently innovate faster without exposure concerns.
Industries competing heavily on sophisticated analytics, from healthcare to finance to e-commerce, find distinct market differentiation in securing and leveraging proprietary insights from their derived data products. Whether employing advanced fraud detection analytics or using creative visualization platforms to deliver actionable insights—like those discussed comprehensively in the article exploring the Tableau definition—rights-controlled data management enhances operational agility and accelerates innovation cycles.
Organizations achieve improved collaboration between internal stakeholders and external partners when transparency and clarity exist around derived data assets. Furthermore, clearly defined rights management protocols greatly reduce friction in cross-team communications, facilitating rapid deployment of new analytics capabilities. Ultimately, effective rights management strategies position companies to respond quickly and safely to rapidly evolving analytics demands, turning their data ecosystems into powerful engines of innovative growth.
Conclusion: Prioritize Derived Data Rights Management Today
Implementing comprehensive rights management for derived data assets isn’t simply good governance—it’s a competitive advantage and strategic imperative. Understanding the unique challenges and risks derived data presents should motivate every decision-maker to proactively embed rights management principles within their data analytics frameworks. By investing diligently in processes, aligning stakeholder responsibilities, and embracing automation technologies like parameterized pipeline templates, you can harness your organization’s data-driven potential fully and securely.
Remember, clear, actionable, and automated derived data rights management fuels innovation, compliance, and sustained competitive differentiation. To navigate this strategic data governance domain confidently, ensure your analytics infrastructure seamlessly integrates robust derived data management practices.
Imagine unlocking critical insights from deeply sensitive data without ever compromising confidentiality. Businesses and public institutions frequently face a paradox: the magnitude of insights analytics could provide and the caution necessary to safeguard sensitive information.
Fortunately, advanced solutions such as Multi-Party Computation (MPC) exist, providing organizations with secure pathways to collaborate and analyze data without revealing confidential details. In this article, we’ll demystify MPC, exploring not just the technical aspects but also the strategic implications of adopting secure collaborative data analysis as part of your organization’s competitive advantage. Let’s unpack this exciting approach to analytics, arming decision-makers with essential insights that will help them revolutionize their data strategies.
Understanding Multi-Party Computation (MPC)
Multi-Party Computation refers to a set of cryptographic protocols enabling multiple parties to jointly analyze their data without exposing underlying sensitive information.
Imagine healthcare institutions, financial firms, or government agencies securely combining their datasets to identify critical patterns while remaining compliant with stringent privacy regulations. The transformative potential of MPC lies in its ability to execute complex analyses across independent, distributed databases, ensuring no party reveals raw, identifiable, or sensitive data in the process.
The core technical concept of MPC revolves around secret sharing and secure algorithms.
Data submitted to an MPC protocol become encrypted and split into fragments, ensuring no individual fragment contains enough information on its own to compromise privacy.
Computation and analysis occur on fragments that remain separately secured at each location.
By carefully managing permissions and cryptographic security during computation, MPC guarantees robust protection, ushering organizations confidently into a collaborative future of analytics and innovation.
Adopting MPC means businesses can tap into collaborative analytical insights previously hindered by security risks. Typically, data practitioners relied heavily on ETL methodologies; now, innovations like Zero-ETL architecture combine seamlessly with MPC, yielding highly responsive, secure data analytics environments reflective of real-time capabilities.
The Strategic Value of MPC for Modern Businesses
Businesses today operate within vast ecosystems where data integration, collaboration, and insight generation play critical roles. Adopting MPC empowers your organization to enter partnerships that were previously fraught with privacy concerns or regulatory hurdles. For instance, healthcare institutions could enable better clinical outcomes by collectively analyzing patient treatment effectiveness without risking patients’ data confidentiality.
Similarly, financial institutions can better detect and prevent fraud by securely matching patterns across distributed datasets without ever directly exposing confidential customer transactions.
Moreover, Multi-Party Computation enables collaboration-driven competitive advantage. By securely pooling knowledge gleaned from datasets across industry peers or government entities, businesses can vastly amplify their predictive capabilities. Consider accurate demand prediction, for example, where MPC allows organizations across multiple sectors to share aggregate data insights safely and compliantly.
These insights translate into unprecedented accuracy in predicting external impacts from competitors or market changes, ultimately enabling businesses to proactively manage risk and recognize market opportunities.
The strategic integration of MPC into your company’s workflow also highlights your forward-thinking commitment to innovation and privacy.
Future-proofing your business technology stack includes properly scaling your infrastructure; learn more on enhancing capabilities by reading our guide: how to scale your data infrastructure as you grow.
Practical Implementation: Applications and Use Cases for MPC
The real-world applicability of Multi-Party Computation extends across diverse industries, underscoring its strategic versatility. Healthcare, for instance, can utilize MPC to safely evaluate treatments and patient outcomes across multi-institutional datasets.
By doing so, healthcare providers uncover critical insights without compromising patient confidentiality, allowing organizations to improve medical guidelines collaboratively yet responsibly.
A similar justification holds true for public safety analysis.
Municipal governments and public safety agencies leveraging MPC securely share crime statistics and emergency response data to identify crucial patterns and proactive preventative measures. For an in-depth illustration of analytics applied securely at the local level, read our recent article highlighting data analytics enhancing public safety in Austin. MPC, in such settings, ultimately serves as a safeguard enabling informed decision-making without endangering critical individual privacy concerns.
Businesses adopting MPC in data-intensive sectors, such as retail or manufacturing, can also significantly improve forecasting accuracy. MPC facilitates enriching forecasting models by securely integrating competitor insights, regional external factors, and market behaviors. Check our tips on enhancing forecasting accuracy by considering external drivers: enhancing demand forecasting with predictive modeling.
Navigating MPC Implementation Challenges
While adopting MPC provides substantial strategic and operational advantages, implementation isn’t without its challenges. Companies adopting MPC must navigate complexities surrounding computational overhead, latency, and efficient resource allocation to maintain performance levels. Complexity can escalate with large datasets, requiring strategic optimization for compute-intensive operations. Here, leveraging expert consultants specialized in databases such as MySQL proves advantageous, optimizing computational strategies to minimize overhead. Our experienced team provides MySQL consulting services tailored specifically to your organization’s unique analytics ecosystem, ensuring optimal MPC implementations.
Another challenge faced involves managing transactional data consistently across MPC implementations. Effective data loading patterns become critical to ensuring seamless, secure, and consistent analytics execution. Organizations seeking to streamline and enhance their data ingestion workflows may benefit from considering MPC with transactional stability. Check out our article about transactional data loading patterns for reliable, MPC-compatible architectures.
Finally, maintaining trust between collaborating parties presents both technical and organizational hurdles. Establishing well-defined protocols and clear lines of communication proves key to ensuring smooth MPC interactions, enabling partners to feel confident and secure while collaborating effectively.
Ensuring Data Integrity and Visualization in MPC Analysis
Organizations adopting MPC need to uphold high standards of visualization and data integrity alongside underlying security protocols. Data visualization in MPC demands an approach accommodating uncertainty, imprecision, or varying confidence across multi-source datasets. Effective visual communication ensures collaboration partners fully grasp insights generated within the MPC framework. Our article on visualizing uncertainty explores methods ideal for accurately and fairly representing MPC-based analyses, ensuring confident interpretation of secured, aggregated insights.
Moreover, MPC integration requires clear conceptual transitions between multiple analytical states and stages, often accessed via different stakeholders or operational workspaces. Practical implementation relies heavily on advanced visualization and UX design, including concepts such as smoothly implemented view transitions. For data visualizers and product leads exploring context switch effectiveness, examine our insights on view transitions in multi-state visualizations, enhancing readability, communication, and user experience during MPC operations.
Additionally, accurate and reliable MPC-driven analytics depend fundamentally on maintaining database health and cleanliness, often including removal of duplicate, inconsistent, or erroneous records. Explore effectiveness in managing database integrity with our resource on SQL data removal strategies, ensuring robust MPC data foundations suitable for accurate, secure collaborative analytics.
Conclusion: The Future is Collaborative and Secure
Multi-Party Computation is poised to redefine how businesses and institutions interact, delivering actionable insights without sacrificing data privacy or security. As innovative companies adopt MPC, secure analytics collaborations will become a norm rather than an exception. Decision-makers unlocking the potential of secure collaborative analytics empowered by MPC position themselves confidently at the forefront of competitive, data-driven innovation.
At Dev3lop LLC, we champion analytics innovations that deliver business success, privacy compliance, and strategic advantages. We invite you to tap into this powerful technology to unlock immense value from sensitive datasets. The future belongs to organizations that prioritize secure, insightful, and collaborative analytics.
In today’s data-intensive landscape, waiting for static batch analyses to deliver actionable insights is no longer sufficient. Competitive businesses rely on real-time processing of data streams to monitor customer interactions, operational efficiency, security status, and predictive analytics to make informed and instant decisions. Achieving such agility demands handling streaming data at scale, where complex, high-velocity data must be captured, transformed, analyzed, and acted upon within milliseconds. Throughout this article, we’ll guide strategic-level professionals and decision-makers through the evolving landscape of streaming data technologies, key design patterns, and best practices to successfully implement streaming data solutions. Leveraged correctly, the right technologies and patterns can empower businesses to react quickly, enhance customer experience, optimize profitability, and stay ahead of the market curve.
Understanding the Basics of Streaming Data
Streaming data refers to continuous, real-time flows of data generated by event-driven applications, sensors, social media, transactional systems, and IoT devices. As businesses increasingly rely on real-time insights, it’s crucial to comprehend how these high-density data streams differ from traditional batch processing scenarios. While batch processing typically accumulates data over predefined intervals and processes it offline, streaming technology processes data continuously and immediately upon ingestion.
At large organizations, capturing and interpreting streaming data allows stakeholders to respond instantly to emerging business opportunities, mitigate risks in real-time, and enhance operational responsiveness. Streaming analytics offer a transformative way to make use of freshly generated data by immediately detecting events or changes in trends, effectively supporting downstream actions such as executing marketing campaigns, recommending inventory adjustments, or optimizing resource allocation.
Through effective leveraging of streaming data, decision makers can pivot business strategies with greater confidence and agility. For example, companies increasingly use streaming analytics to monitor instant fluctuations in customer behaviors, identify market demands, or forecast supply chain dynamics. As we highlighted in our guide to mastering demand forecasting with predictive analytics, real-time insights help enable strategic agility and operational efficiency in complex business environments.
Technologies for Managing Streaming Data
Apache Kafka: Robust and Scalable Data Streaming Platform
When discussing streaming data technologies, Apache Kafka quickly emerges as a powerful and scalable event-streaming solution that plays a vital role in modern real-time data architectures. Kafka is designed to handle millions of events per second, enabling organizations to capture, store, and provide real-time access to data across the enterprise effectively. Kafka acts as an event distribution and buffering mechanism, efficiently decoupling data producers and consumers in a highly scalable event-driven architecture.
Kafka owes its popularity to reliability, fault tolerance, speed, and data streaming flexibility. It allows data engineers and architects to construct real-time pipelines effortlessly while handling data consistency across applications and processes. As a message broker platform, Kafka integrates seamlessly with processing systems such as Apache Spark and Flink to deliver sophisticated real-time analytics and rapid data-driven decision-making. Alongside our expertise consulting on modern technologies, including Node.js-based services, Kafka helps organizations unlock powerful streaming data analytics efficiently and reliably.
Apache Spark and Flink: Advanced Stream Processing Frameworks
Following Kafka’s ingestion of event streams, Apache Spark Streaming and Apache Flink present powerful stream processing engines. Spark Streaming offers micro-batch processing, allowing organizations to apply advanced analytics, machine learning, and predictive modeling on streaming data. Flink goes further, with a true event-driven streaming model capable of processing data at ultra-low latencies, thereby providing immediate value through real-time event detection and analytics.
Flink additionally offers features such as exactly-once stateful streaming, ensuring accuracy, reliability, and consistency in stream processing environments. Enterprises leverage Apache Spark’s user-friendly APIs and scalable performance to rapidly implement exploratory analytics, predictive modeling, or seamless integration with visualization tools such as Tableau—to present insights through compelling reporting, dashboards, and advanced visual analytics. For those looking to reduce latency even further, Flink provides extraordinarily responsive real-time analytics, especially valuable in scenarios such as fraud detection, network monitoring, or responsive supply chain optimization.
Essential Streaming Data Patterns and Architectures
Event-Driven Architecture (EDA)
Event-driven architecture forms the backbone of most modern streaming data platforms. In an EDA approach, messages or events are generated and immediately published to a message broker or streaming data platform like Kafka. Subsequently, event consumers read these events independently, allowing decentralized and asynchronous system architectures. Through this decoupling mechanism, each individual system or application’s responsiveness is dramatically enhanced.
From fraud detection systems to inventory management applications, EDA provides businesses with the flexibility and adaptability to respond efficiently to rapidly emerging data scenarios. It not only improves organizational agility and scalability but also enhances decision-making capabilities within real-time analytics platforms. For instance, our expertise in optimizing inventory levels often involves leveraging event-driven streaming data analytics to avoid stockouts or overstock challenges in real-time supply-chain contexts.
Real-Time Stream Analytics Architecture
A robust real-time stream analytics architecture is essential for enterprises looking to effectively harness streaming data. Such architectures typically involve streaming data ingestion flowing into a powerful processing framework (Apache Spark or Flink), sophisticated analytical processing performed on these streams, and subsequent visualization of results to aid decision-making. Real-time analytics platforms often leverage data visualization technologies like Tableau, enabling stakeholders to interactively understand data in context, empowering insightful and timely decisions.
Learn more about visualizing streaming data effectively through our expert guide on the power of data visualization, which underscores how instantaneous analytics enhance business agility and corporate responsiveness.
Key Considerations: Ethical Responsibility and Data Governance
As organizations rapidly adopt streaming data architectures with real-time analytics, decision-makers must proactively anticipate ethical implications around data collection, privacy, and responsible data usage. Real-time monitoring generates immense insights into consumer personas, behaviors, and sentiments. But as highlighted in our overview of ethical considerations of data analytics, business leaders need actionable frameworks to responsibly avoid privacy intrusions and prevent inadvertent biases in analytical models.
Proactively embedding data governance rules and privacy-preserving systems into streaming data architectures allows businesses to maintain user trust, comply with regulations (such as GDPR and CCPA), and execute data-driven decisions without creating ethical concerns. Strong data compliance models, anonymization and encryption mechanisms, and clear communication of privacy policies become critical components to uphold ethical data management and analytical transparency.
Cost Efficiency and Return on Investment (ROI)
As with any major architectural investment, financial considerations guide decision-makers toward optimal choices. Implementing streaming technologies demands strategic alignment of investments against expected business outcomes. Enterprises must assess total cost of ownership by evaluating factors like infrastructure scaling costs, cloud provider options, licensing models (such as understanding Tableau pricing if visualization platforms are utilized), and ongoing operational costs.
Investing in streaming analytics, however, promises substantial ROI in agility, competitive advantage, efficient resource allocation, and increased profitability through actionable real-time insights. Greater visibility into market dynamics or supply chain demands allows businesses to reduce response latency, minimize inventory holding costs, improve operational efficiencies, and maximize profitability over time. By strategically leveraging streaming data to bolster efficiency and identify cost drivers proactively, technology investments return significant sustained value to enterprises.
Conclusion: Empowering Your Business with Streaming Data
Streaming data presents undeniable transformative opportunities toward innovative, agile, and revenue-driven business operations. By strategically leveraging modern technologies like Apache Kafka, Spark, Flink, and advanced visualization platforms, organizations can harness real-time analytics for impactful decision-making. Adopting smart architectural patterns and remaining mindful of data ethics and ROI considerations further positions enterprises for success.
As recognized experts in data analytics and innovation, our experienced team is poised to help you navigate technology intricacies for sustained business advantage. Whether it’s Node.js consulting services or integrative real-time data solutions, we empower industry leaders to embrace the future today and turn data into catalytic growth drivers.
In today’s data-driven world, visualizations serve as the gateway to actionable insights. However, simply presenting data isn’t enough—users demand control that allows dynamic exploration. Visualizations become even more powerful when users can interact effortlessly, intuitively surfacing insights tailored to their needs. Interactive legends, by providing simplified methods for filtering, selecting, and focusing data directly within visualizations, not only empower users but significantly enhance comprehension, analysis, and decision-making speed. In this blog, we’ll explore how interactive legend techniques transform visualization efficacy, driving smarter analytics and strategic decision-making.
Why Interactive Legends are Crucial in Data Visualization?
When decision-makers have limited interactivity within visualizations, they often struggle to uncover critical trends effectively. Effective data visualizations should allow users to effortlessly filter and isolate data points, thereby gaining deeper understanding quickly. Traditional static legends provide reference points but don’t allow users meaningful control. Conversely, interactive legends enable viewers to directly influence the displayed data by toggling, selecting, or isolating categorical segments—capabilities that are crucial for faster data analysis and enabling informed decisions.
Organizations increasingly leverage advanced data analytics solutions by embedding interactive components into visualizations, guiding strategic choices with confidence. Using dynamic legends in visualizations closely aligns with successful analytical strategies revealed through practices like dimensional modeling, enabling users to quickly identify meaningful relationships between dimensions and metrics. Consequently, executives and analysts empowered with interactive visualization capabilities gain quicker actionable insights and leverage a stronger competitive advantage—making more informed strategic choices.
The Advantages of Interactive Legends for End Users
Improved Data Discoverability and Exploration
One of the prime benefits of interactive legends lies in unlocking hidden relationships in your data. By enabling users to select or deselect categories within the data visualization directly, interactive legends simplify the discovery of critical trends otherwise obscured by complexity. This powerful method transforms passive viewers into active explorers, enhancing their ability to uncover insights swiftly by personalizing the dataset visualized on-demand.
For example, in predictive scenarios—and those driven by external variables—interactive visualizations with legends simplify isolating and examining specific external trends. For instance, as we have detailed previously in our article on enhancing demand forecasting using predictive models with external factors considered, the user’s ability to select relevant external variables directly can greatly enhance model understandability and accuracy from a visualization standpoint.
Facilitating Faster, More Accurate Decision-Making
When business leaders face complexities presented by modern datasets, decisions often get delayed if visualizations lack accessible user interactions. Interactive legends facilitate faster decision-making by allowing decision-makers to easily isolate relevant data segments without cumbersome interactions. Executives can rapidly filter through extensive aggregation layers and detailed levels without requiring a time-consuming drill-down, significantly enhancing the responsiveness of their decisions.
This capability becomes even more crucial within security and fraud detection contexts. In analytics scenarios, such as those discussed in our analysis of stopping fraud proactively with data streaming technologies, enhancing visualization interactivity helps administrators quickly pinpoint fraudulent behaviors. Empowering users to directly toggle data points via interactive legends results in quicker identification and response to abnormal data trends and activities.
Implementing Interactivity Effectively
Choosing the Right Visualization Framework
Successful implementation of interactive legends depends heavily on choosing the appropriate visualization framework. Modern visualization technologies such as Tableau, Power BI, and custom JavaScript libraries (e.g., d3.js) intrinsically support interactive legends and selection features for user-driven data exploration. However, architectural decisions must also align with backend integration and real-time data needs—for instance, visualizations running on data warehousing solutions may require expert database integrations. Utilizing interactive visualization capabilities aligns seamlessly with database-centric consulting expertise like our own MySQL consulting services, ensuring streamlined and performant data connection pipelines.
Additionally, effective interactivity implementation often calls for deeper architectural integration layers. For example, robust dimensional modeling best practices, discussed in our prior blog post exploring Lambda architecture for stream and batch unification, can greatly enhance visualization responsiveness and real-time interactivity. Such robust structures significantly improve user experiences with interactive legends, permitting instant data toggling, slicing, and exploration throughout complex visualization layers.
Deploying User-Focused Data Design Strategies
Technical implementation alone doesn’t assure interactive legend effectiveness; user experience considerations stand paramount as well. Effective interactive visualizations employ clear graphics, intuitive legend placements, and color selections optimized for accessibility and ease of use. Strategic design decisions aligned with data architecture best practices dramatically heighten user satisfaction and efficiency from visual analyses.
Advanced design considerations include addressing localization and linguistic context using custom language-aware collators as detailed in prior explorations of data processing language adaptations. These ensure interactive legends can be meaningfully delivered to diverse, global audience bases, offering comprehensive interactivity and control regardless of language barriers.
Advanced Considerations for Enhancing Interactiveness
Integrating AI and Machine Learning Capabilities
Integrating interactive visualizations with AI-driven insights can further expand their power—particularly for large, complex data scenarios. Solutions incorporating AI techniques previously explored in our blog post on vetting and discovering trustworthy software engineers using AI-driven vetting approaches exemplify how visualization interactivity can seamlessly incorporate intelligent, contextual recommendations for analysis, significantly amplifying decision-making capabilities.
Smart interactivity can dynamically personalize visualization elements, adapting user interactions with legend selections prioritized by predictive analytical suggestions. Such capabilities drastically simplify exploration complexity, improving user confidence and facilitating more insightful, tailored analyses.
Real-Time and Streaming Data Visualization Challenges
Integrating interactive legends effectively within real-time or streaming data visualizations requires additional technical expertise and thoughtful consideration. Streamlining these interactive visualizations demands efficient architectures for handling vast, continuously updating data streams, as showcased in our comprehensive guide covering bidirectional system synchronization patterns and data flows. Building these interactive experiences on robust architecture foundations ensures consistent performance, even with extensive interactions and continuous real-time updates.
Additionally, complex interactivity may benefit from advanced processing techniques for streamed data, such as those covered extensively in our broader articles on data streaming and proactive intervention in analytics contexts. As interactive legends respond dynamically to real-time data actions, incorporating robust infrastructure remains paramount for delivering smooth, scalable interactivity experiences.
The Strategic Value of Interactive Legends Today and Beyond
As analytics maturity develops within organizations, visualizations continue evolving towards greater user-driven interactivity. Interactive legends represent an elegant yet extraordinarily valuable improvement, significantly empowering users to rapidly derive insights, make informed decisions, and foster trust in their data analytics systems. To maximize these benefits, organizations should consider establishing dedicated expert teams, reflecting our discussions on why your first data hire shouldn’t necessarily be a data scientist, to thoughtfully embed interactive legends into internal data analytics practices.
Incorporating interactivity effectively signifies not just technical expertise but a strategic shift toward embracing true data exploration paradigms. Done right, interactive legends dramatically streamline analysis cycles, ensuring organizations can continuously uncover new opportunities hidden within their data assets in today’s—and tomorrow’s—competitive business landscape.
Ready to empower your visualizations with enhanced interactivity and actionable user insights? Reach out today and leverage our expertise in analytics consulting, visualization strategy, and custom data solution development to elevate your organization’s analytics journey to new heights.
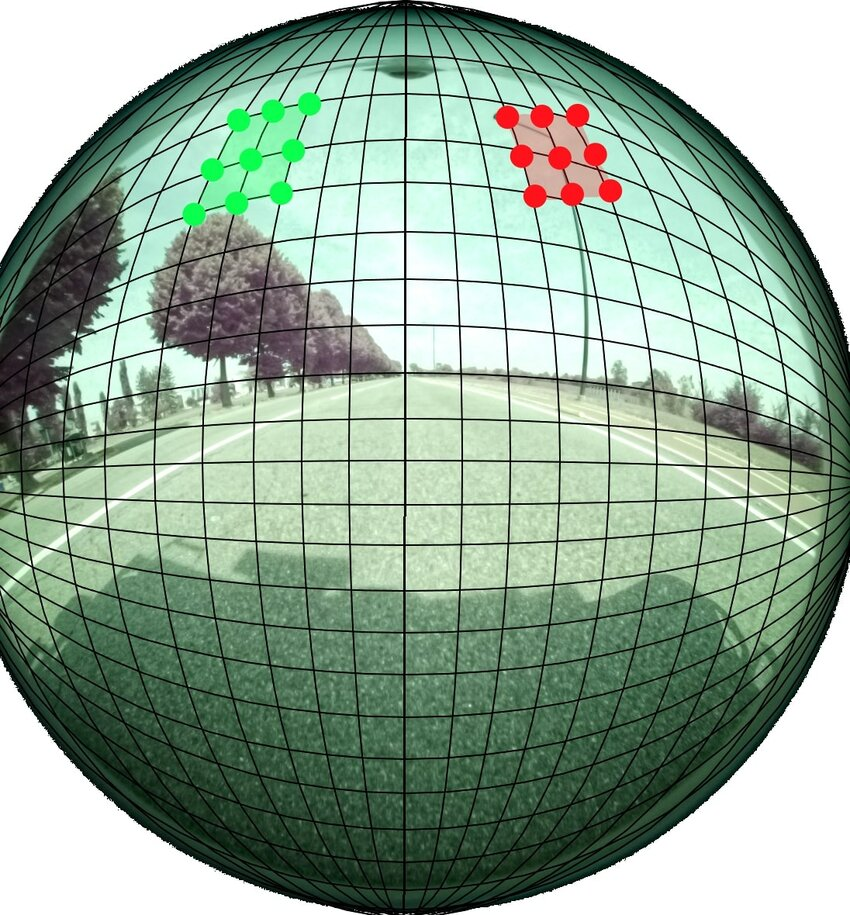
In the modern landscape of data analytics and visual exploration, the ability to quickly isolate critical insights within extensive datasets can be a major determinant of competitive advantage. Imagine if you could swiftly zoom into a critical data insight without losing the overall perspective of the broader context. The fisheye distortion approach makes this possible, simulating the effect of a magnifying glass that enhances your focal area while maintaining peripheral visibility. When properly implemented, fisheye techniques offer decision-makers, analysts, and innovators a superior way to navigate large datasets, ensuring they never lose sight of critical context. In this article, we explore this method’s core principles, advantages, potential use-cases, and technical considerations that empower decision-makers with advanced data visualization capabilities.
Understanding Focus+Context Visualization and Fisheye Distortion
“Focus+Context” visualization, in simple terms, enhances user experience by enabling simultaneous detail-oriented exploration and broader contextual awareness. Traditional visualization methods often require users to zoom in excessively, causing them to become disconnected from crucial surrounding data. This dilemma is where fisheye distortion techniques shine. The method primarily leverages nonlinear scale transformations, presenting regions around focal point data in finer detail, while regions farther away shrink progressively to maintain systemic visibility.
Fisheye distortion, adopted from the natural optics of fish eyes, leverages the power of perceptual psychology, allowing software to mimic human visual perception. It magnifies the user’s focal area while retaining contextual representation of the overall dataset. This visualization approach ensures analysts never become isolated in limited data viewpoint—instead, they remain contextually aware, evaluating details and relationships securely within the scope of the entire dataset.
Today’s data-intensive organizations, particularly those leveraging complex databases such as SQL server environments, can greatly benefit from fisheye distortion. Our Microsoft SQL server consulting services provide the expertise needed to efficiently integrate advanced data visualization systems, including fisheye methodologies, resulting in smoother analytics processes and decision-making capabilities.
The Technical Foundation: Fisheye Mathematical Formulations
At its core, fisheye distortion relies upon mathematical transformations such as nonlinear scaling functions to distort spatial representations intentionally. A conceptual variation of the “degree-of-interest” (DOI) function, developed through works of information visualization pioneers like George Furnas, commonly defines areas of interest by combining parameters such as the user’s focal point and the dataset context.
The DOI function typically calculates a value determining how much emphasis or visual magnification to apply at specific dataset coordinates. The equation usually integrates both the intrinsic importance of a data item (often called its “a priori” interest) and extrinsic importance based on proximity or relevance to a focused area. Thus, objects near the user’s point of interest get emphasized prominently, scaling down smoothly toward peripheral areas. Applied effectively, this mathematical model delivers visually appealing, intuitive, and interactive displays.
Moreover, carefully engineered fisheye implementations allow for flexibility and customization. Engineers can fine-tune how distortion behaves with user interactions, ensuring robustness and value. Building a data-intensive system optimized for interactivity involves significant engineering challenges. You can review how our team approaches scaling complex data platforms capable of handling massive daily interactions in our recent data engineering case study.
Applications in Real-world Decision-Making
Fisheye distortion serves well across various industries and contexts, particularly where quick and precise navigation of large datasets is crucial. For example, financial organizations dealing with vast market data find value in fisheye visualizations. Traders can instantly highlight market anomalies or fluctuations without losing their grasp on overall trends and pricing movements.
Cybersecurity teams empowered by fast-paced analytics tools can visualize extensive data streams contextually, instantly detecting and reacting to threatening anomalies. Read more about the power of real-time data streaming approaches in fraud detection scenarios in our article, The Role of Data Streaming: Stopping Fraud Before It Happens.
Beyond finance and cybersecurity, fisheye distortion offers profound advantages in consumer data analytics. Retail organizations can identify consumer buying patterns and market shifts while visualizing intricate relationships between revenue streams, sales channels, and individual customer segments. This holistic yet targeted approach drastically improves executive-level clarity and decision-making suitability.
Companies within tech-savvy business communities, such as those in tech hubs like Austin, are utilizing advanced analytics practices. To better understand industry trends and data-driven operations improvements, consider our insights into how Austin-based companies are using data analytics to improve their operations.
User Experience and Fisheye Visualization Tools
User experience (UX) plays an essential role in data visualization applications. Excellent UX facilitates smooth interactions while keeping visual clutter minimized. With fisheye distortion techniques, interfaces can offer intuitive zooming mechanisms and responsive transitions. This simplicity allows users to instantaneously alter their area of interest without sudden disruptions or visual disorientation.
Efficient implementation of a fisheye interface goes beyond elegance; it requires thoughtful inclusion within interaction and visualization design workflows. Navigating data and characteristics effortlessly through interactive fisheye interfaces enables users to focus their cognitive energy on insight extraction rather than manipulation frustrations.
Organizations interested in embracing fisheye-style visualization for their data visualization solutions can benefit from pairing it with storytelling-driven visualizations that resonate deeply with stakeholders. Discover more about enhancing analytics with compelling visual storytelling in our article dedicated to The Art of Storytelling Through Data Visualization.
Overcoming Common Challenges and Ethical Implications
While fisheye distortion brings groundbreaking improvements to large-scale data analysis, it is vital for decision-makers to recognize and overcome potential challenges. For newcomers, the nonlinear scaling involved can occasionally introduce confusion if applied without essential limits, potentially obscuring important insights unintentionally.
Ensuring users understand how fisheye visualization works and offering options to adjust distortion levels are key to successful deployment. Engineering teams will benefit from robust testing processes to discover the optimal balance between context visibility and focal-area magnification, avoiding potential pitfalls.
Furthermore, ethical considerations in presenting distorted visualizations must not be neglected. For decision-makers, understanding data context and sharing transparency in representation is critical. Highly interactive visualizations may unintentionally bias users if not designed appropriately, potentially skewing data-driven decisions. Explore more about the significant role ethics plays in creating trustworthy analytics systems in our article detailing Ethical Considerations in Data Engineering and Analytics.
Integrating Fisheye Visualizations: CI/CD and your Analytics Workflow
An essential part of deploying sophisticated visualization solutions like fisheye requires solid software engineering practices. Establishing and maintaining these complex visual analytics components demands a well-structured backend and release pipeline. Continuous Integration/Continuous Deployment (CI/CD) ensures you can reliably update and enhance visualization systems without interruptions or downtime.
Effectively leveraging CI/CD within the fisheye visualization pipeline helps maintain usability, stability, and rapid deployment capabilities in response to changing business needs. If you’re unfamiliar or looking to enhance your current deployment processes, our team provides a comprehensive guide on proper CI/CD deployment strategies. Read about best practices for establishing continuous integration and delivery processes in-house on our helpful tutorial: Building Your CI/CD Pipeline: A Comprehensive Guide.
Conclusion: Driving Intelligent Decisions Through Effective Visualization
Fisheye distortion for focus+context visualization is about harnessing accuracy and context without sacrificing one for the other. It empowers organizations to enhance productivity and clarity, reducing cognitive load and interactivity complexity. Embracing the power of targeted innovation in visual data exploration allows data teams and organizations to arrive at value-driven insights rapidly.
When paired with expert guidance, advanced analytics, and experienced data engineering, fisheye distortion enables organizations to scale visual data exploration to new heights—driving deeper insights, expanded analytics capabilities, and sharper strategic decision-making.