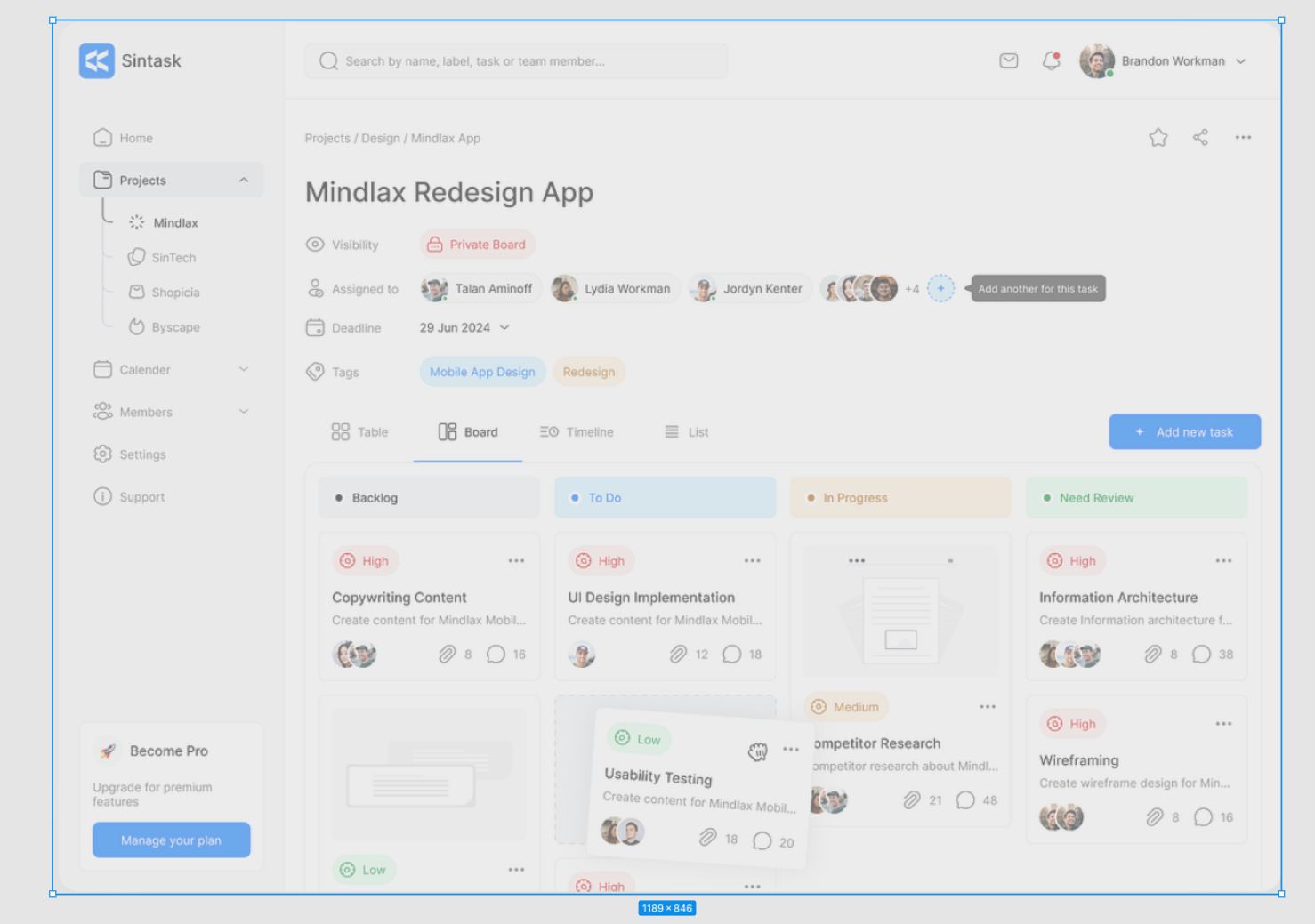
Real-time presence indicators is a cool feature request coming to your backlog. If you need to improve your companies software, DEV3LOP is here to discuss real-time presence indicators!
I spent many nights creating a new software Vugam, but now I need to make my software better. What do I do? Real-time presence indicators could be the next step in the equation.
However if you’re like me, you’re calling this multiplayer, or tracking cursors. Perhaps it’s the ability to see someone is typing in slack, or that there’s a green icon in zoom if you’re online. Some people are never online, and it’s really obvious via zoom icon indicator.
Does your software need multiplayer?
Do you want multiple users working together in a collaborative environment?
Are users working together on similar problems?
Are users using single player software that is built to collaborate with other people?
My first time seeing real-time indicators was while using GoogleSheets and GoogleDocs in college, however no cursor indicators and limited capabilities had me wondering, what’s next… But not being in the software engineering path, being focused on information system, I felt a little disconnected from the technology.
This blog discusses improving user experience with collaboration, the differences between what to stream real-time and what to store in storage, and the balancing act of how to manage real-time data flows.
I need to create a user experience that allows end users to come together.
But once that software is done, how do I improve? Perhaps, real-time presence indicators… Using websockets.
Hi, I’m Tyler, I’m interested in adding real-time presence indicators into new projects and in our future software releases. One in particular is creating a multiplayer analytics software, however how the heck do I make a software multiplayer? Friends have told me this is a stretch and a lot of work…
I’m naive, I didn’t believe them. Created websockets/multiplayer in a day, and created a bit of a problem. I wasn’t thinking about what should be persistent between sessions VS streaming. This caused a lot of bugs. But lets take these lemons and create a drink.
Javascript VS HTML (legacy) in this screenshot.
Why a Server and a Database Are Essential (and Why the Cursor COULD stay Ephemeral)
When building real-time web applications, one of the biggest decisions is how and where to store data. Not knowing how to do this yourself is a cool maze of learning that I’d like to explain to you, for business users, and technical people who are interested in transitioning into a more technical space!
Some might assume that a websocket alone can handle everything, but this misses a crucial point: you need a server and database layer to keep important data secure, consistent, and reliable. Some may even start learning “acid compliance” to further explore the rules of a database.
Following down a path of creating a websocket software that didn’t consider what should be persistent in a file or database, VS streaming in websockets is where I have fallen a victim, but in the mistake I found this is likely not common sense to business users who desire this request…
Real-Time Presence Indicators: The server acts as the backbone, ensuring everything runs smoothly and logically
Again, the server acts as the backbone, you’ll need a server to use websockets and the backbone is used to ensure everything runs smoothly and logically!
The database (or perhaps document storage) preserves what actually matters—data that should last beyond a single session or connection. But not everything belongs in the database. Take the cursor: it’s a dynamic, real-time element. It doesn’t need to be saved, tracked, or tied to a user’s identity. Let it stay ephemeral, moving freely through the websocket.
This approach doesn’t just streamline the system; it respects user privacy. By not storing or analyzing every cursor movement, users can trust they aren’t being monitored at this granular level. It’s a small but meaningful way to give control back to the user.
Why real-time cursor trackingHas Stuck with Me
My goal is to make real-time cursor tracking and communication a cornerstone of the web applications I build in the future. It’s a tool I’ve come to value deeply, largely because of the success I’ve seen with platforms like Figma.
Real-time collaboration is more than just a feature; it’s a way of thinking. Working with it teaches lessons about system design that stick with you—lessons that make you better at building solutions, even if you’re not the one writing the code.
The nice thing about creating a real time cursor tracking software yourself is that you run into the troubles of not knowing better, and this is the best teacher. Whether to use express or websockets, an exciting time.
There’s also a balancing act here that matters: Real-Time System Management
Real-time systems shouldn’t come at the expense of user privacy.
Knowing when to store data and when to let it flow naturally is key—not just for performance, but for creating systems that people can trust. Perhaps that system is one that doesn’t LEARN on your users and create a product within the gray area.
For me, this isn’t just a technical challenge—it’s an opportunity to build better, smarter, and more thoughtful applications. Want to learn more, simple, contact us now.
Building dashboards in PowerBI quickly is important because decision makers are eager to start using these rocket ships we are creating. However, if you’re new to PowerBI that may be asking a lot! Tracing is helpful because it empowers us to quickly create a solution and design from scratch.
What is tracing? Drawing over lines on a superimposed piece of transparent paper, and with figma, you will be able to do this digitally speaking. Allowing you to trace over any designs to abstract your own.
Tracing dashboards is a good way to recreate something net new and offers a fast path for getting people talking about your dashboard designs.
In this article, you will learn to become a master of making powerful designs from scratch, and this will empower you to Create dashboards in PowerBI quickly. Here’s a lot of screenshots to show you what you’re going to be building and potentially a template you can copy and paste into your next PowerBI Design.
Create visual documentation for PowerBI Design
Here at DEV3LOPCOM, LLC, we passionately believe visual documentation improves project deadlines. Plus, allows for fast data product creation and we want to show you how we would create a dashboard from scratch without any direction on the style or design.
Figma works, but any app that allows tracing over an image will work, and in this blog we will show you how to create this template.
We show the steps to tracing the design, and adding it to PowerBI. This can help you operationalize your templates and improve your dashboarding speed across any dashboarding product.
About this PowerBI dashboard Data and our Goals
First, lets learn about the data and establish goals about our workload to keep us focused on an objective.
All data should have a brief description, otherwise it’s hard for others to collaborate with your data sources.
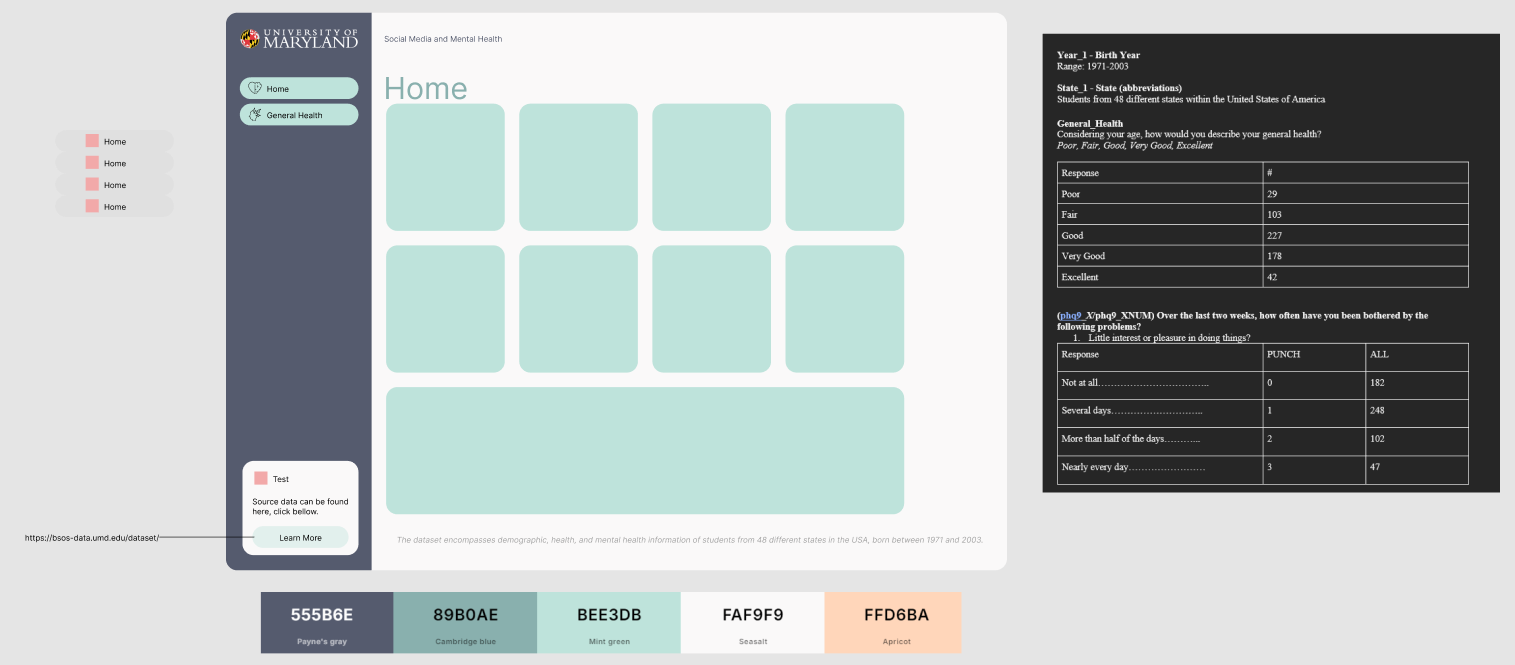
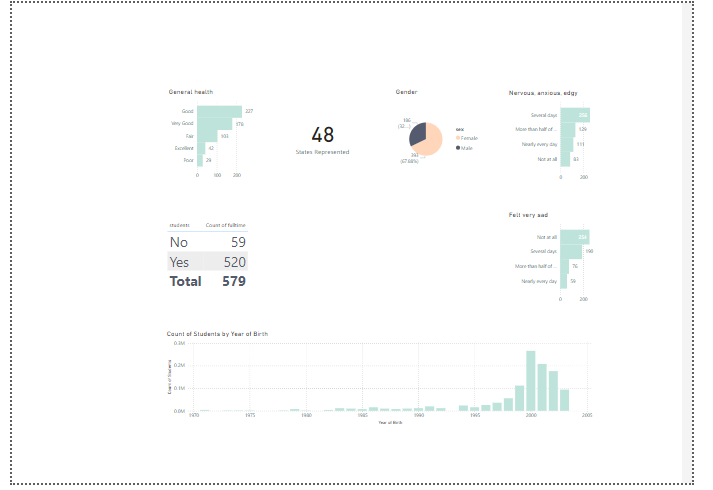
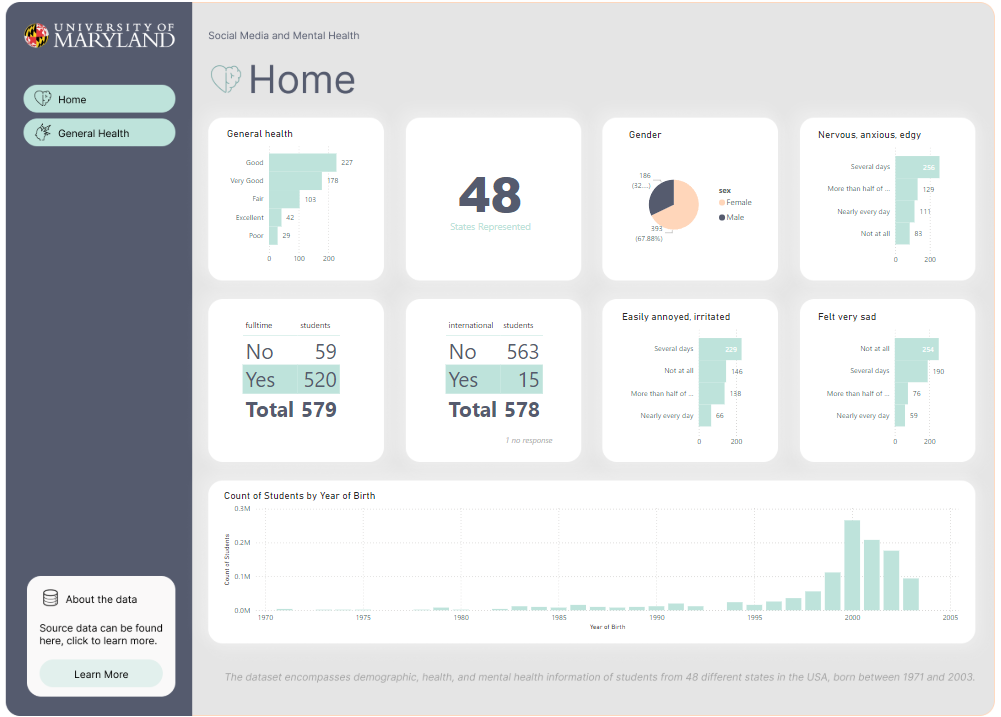
Using the following data about Social Media and Mental Health, was recently released by University of Maryland in July 2024.
Our goal is to quickly generate a dashboard to help others learn PowerBI. However we have thin requirements, it’s fun to pretend this is a real world software consulting engagement, and similar to a real world use case in a busy business environment, perhaps people are too busy to give us insights.We must research and learn on our own.
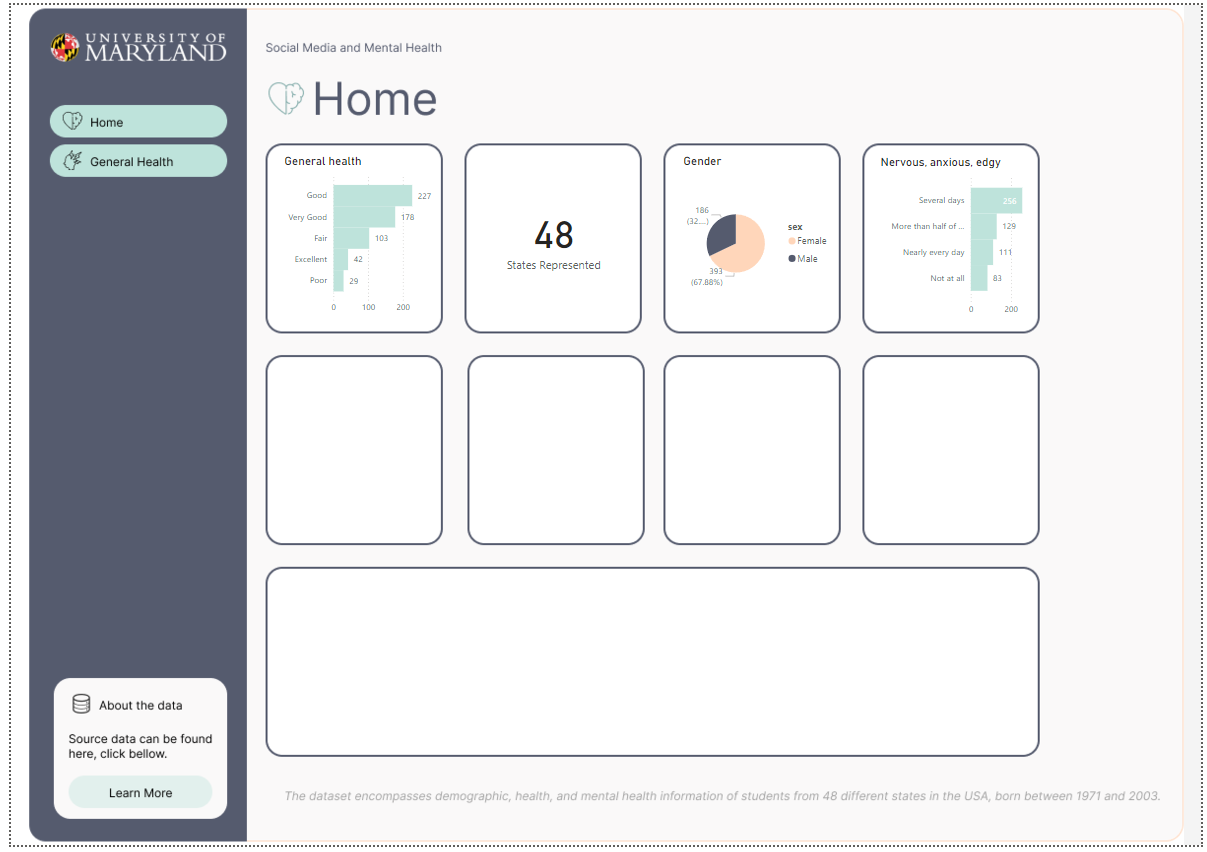
About data: The dataset encompasses demographic, health, and mental health information of students from 48 different states in the USA, born between 1971 and 2003.
How do I get my CSV Data into PowerBI?
Open your PowerBI software. You don’t need to buy anything, just go grab the software and get started with me.
In the Home tab, click Get Data. Then select Text/CSV.
Once we have our CSV data open, you may notice we have weird Column headers that aren’t sensible to anyone on the dashboarding end.
This is typical in a lot of APIs, Data Warehouses, and Data Engineering in general is ripe of columns not being named correctly for each team. Luckily for us, PowerBI can change column names with great ease.
Finding Artwork to Trace Your Dashboard
First, we need to start with learning about “artwork.” When learning to draw, an art teach will ask you to trace something 100 times, and then by the 100th time you’ll be drawing it better.
Same with the internet, we often are reverse engineering each others design to improve our design. In this process we will find some artists we enjoy, choose one, and trace our dashboard on this design.
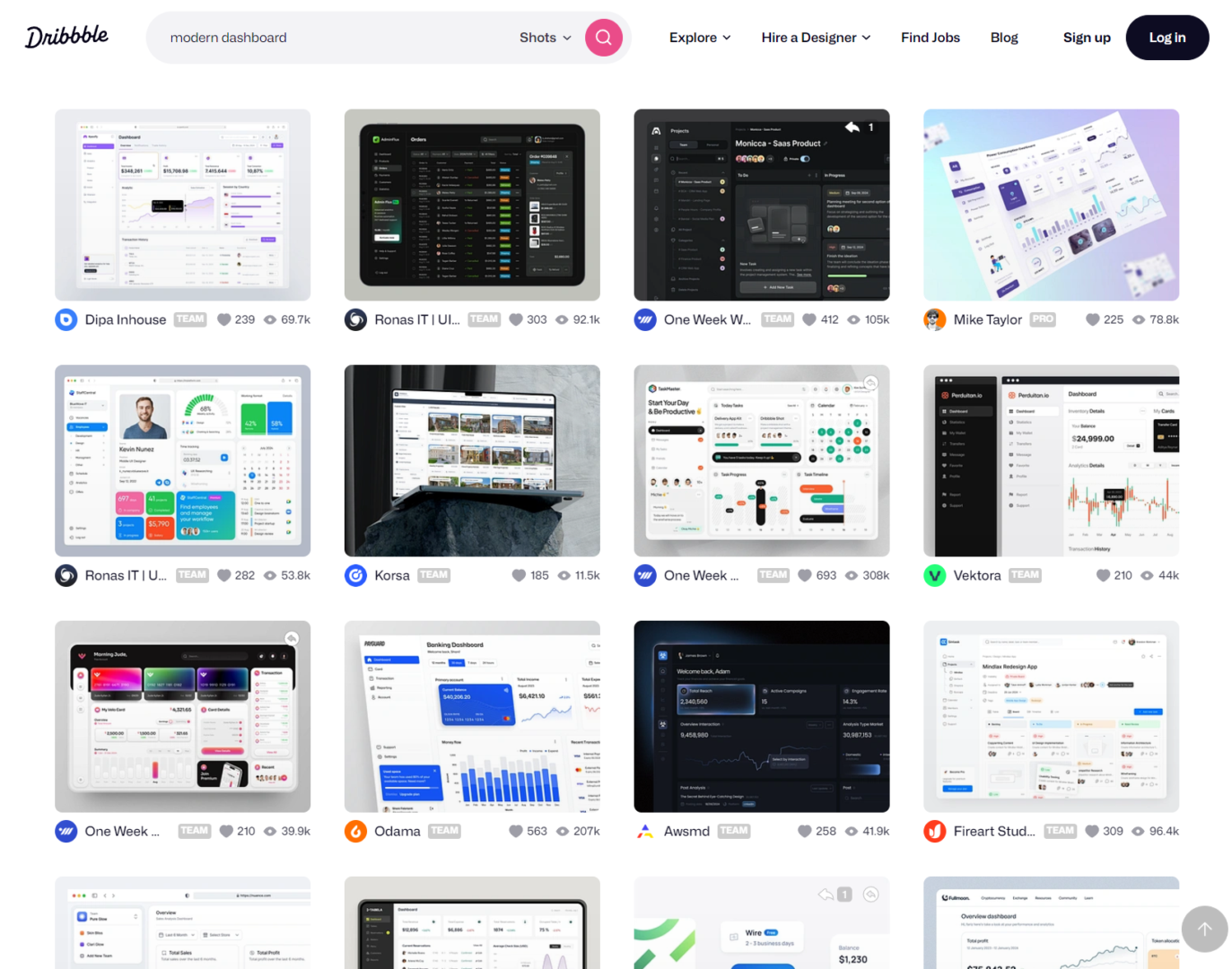
I like using Dribbble to find ideas and learn about modern approaches. It has a lot of really stylish content, and it’s easy to start here as a dashboarding guru.
I search for ‘modern dashboard style…
If working with a client, I will find 3 designs and then ask them to choose one. Then I’ll build everything around this template. I like using figma because it’s easy enough for people to dig into the weeds, and see they can access the design elements.
Pretend our client suggest the following design.
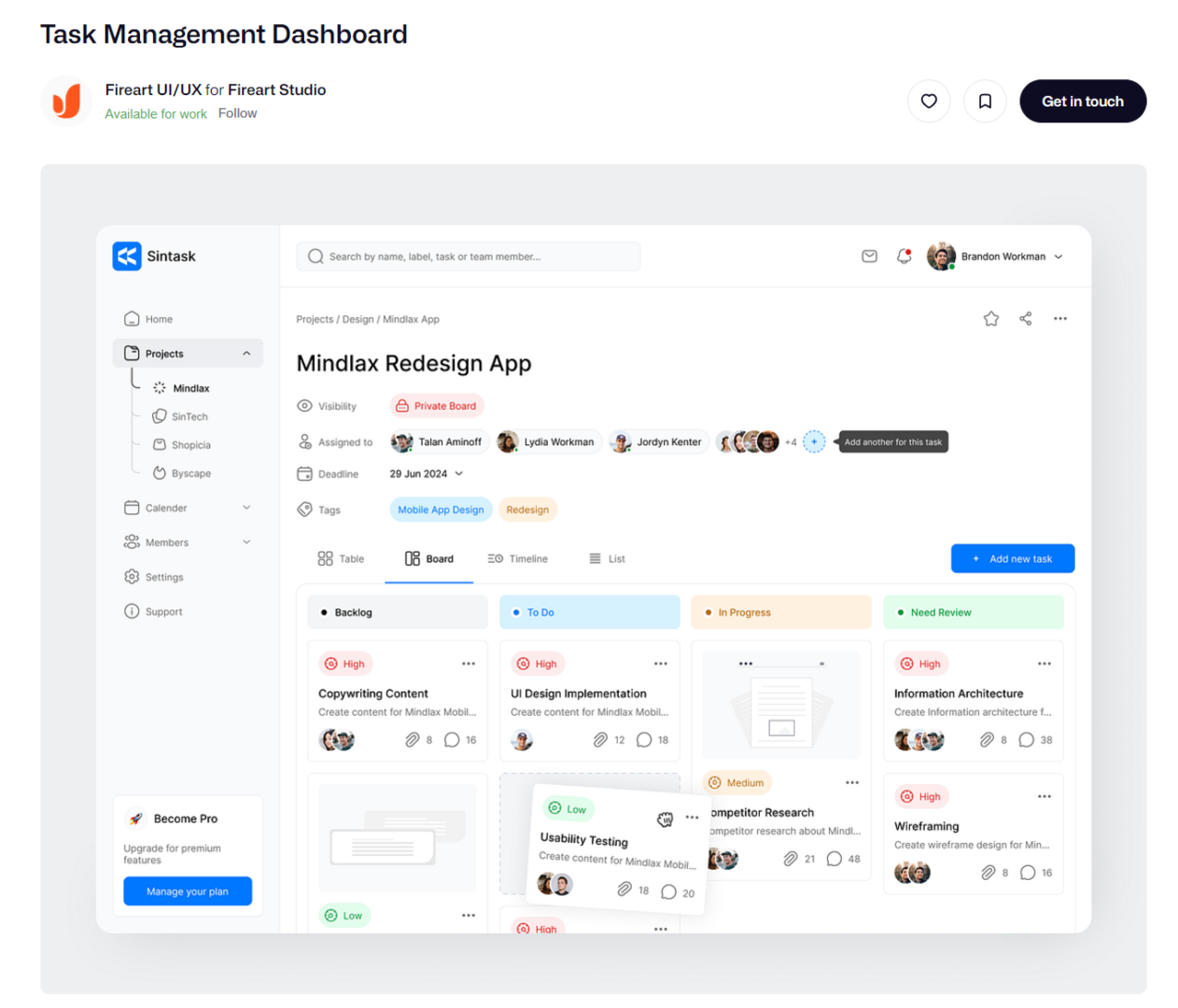
Okay, paste the dashboard we are asked to mimic into figma and lets start tracing.
You’ll notice as you do this you’ll start to create your own unique design to your dashboarding solution.
Start tracing design for PowerBI Dashboard
Cover the surface with a square.
Once hidden completely, lets edit transparency hitting 5 on keyboard. This should adjust the transparency.
Okay, keep flowing. Next same thing for side menu. Trace it. But before we go, adjust the edges to be rounded.
Easy enough in figma, grab little white ball and pull it down until it hits the line we are tracing. adjusting one side adjust all 4 sides.
Okay, hit the side menu.
Next, TEXT overlays. And button overlay with squares.
I prefer starting with a highlighted button so i know the sizing, then replicate that size across. Alt drag and drop for similar copy paste of previous object.
Working through buttons should be easy, let the software guide you to make it perfect too. Notice this has a 7 pixel gap.
Skipping ahead…
Now that we have this style, lets see what it looks like in PowerBI.
Adding your Figma design to PowerBI is simple. It’s a file.
Export the file to your computer.
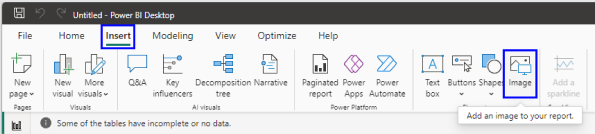
Add image to PowerBI.
Resize dashboard so it fits cleanly.
Remove padding, this is my least favorite thing to have to do in Tableau and PowerBI. These apps automatically pad everything for some reason, haha.
Making decisions about our new Figma Style for PowerBI
In the beginning stages it’s about speed and repeatability. In more advanced dashboard development Figma saves a lot of time.
Next, lets duplicate our work area, and move the sub button navigation for today to the right side.
This is good enough for PowerBI. But before we leave just yet, lets dive into how we can improve the color pallet. I’m using coolors for an easy one.
Now, start to style your dashboard so that it’s appealing. Don’t spend too much time here because chances are the design will change, and you’re just trying to make it look decent. Use corporate colors so you’re following the “designers” pattern. They can send your a pdf file with the correct style guide, which improves this process, but today we are tracing and coming up with our own style guide.
As you’re applying color, start to focus on subtle details…
Improving PowerBI Dashboard with Logos, Style, and Strategy
Logos make dashboards pop. You know you can easily grab one, so grab the most recent logo. Don’t edit peoples logos, use what they supply online.
I’m choosing the source data logo, to help represent the source information because putting my logo here would not be a factual representation of the effort.
Now, notice what happens when I size it next to the buttons, depending on your screenshot and size of dashboard to be traced, in Figma, it’s subtle… Notice my sizing is subtly off and I can’t seem to make it exact, I generate black guide bars… aim to sync up for “perfect”… people will use your dashboard more often if it’s synced up.
In this example/screenshot I’m demonstrating how lining up this logo is a little more tedious than allowing figma to define things by snapping edges, I created black guide lines to help me follow a consistent flow from top to bottom. This is a kind of “hawk eye” or “pixel perfect” strategy I need you to deploy to create powerful dashboards in any reporting software or designed front-end!
Before we part, a few more subtle wins to consider as you perfect your traced design for PowerBI.
This will give a very nice clean view. In figma, click the red square, paste the image. Very easy process if you created the space for the icon. As you do this selection of icons, realize nothing is perfect, we are prototyping, get something in there because that’s the key, fast/repetitive!
Notice how we made some decisions that moved us away from the original design, this is called “making it your own.”
One more layer of decisions to clean it up.
The strategy here is making things clean and lined up, using LINES to guide ourselves. Delete these guide lines once you’ve mastered this technique and keep duplicating to avoid having to do this process again…
Here’s my work station, notice I’m starting to document what goes inside of buttons, and the documentation is in the same screen. This helps with identifying where our hard work belongs.
The header looks a little close to the first square, however a good starting point, we can optimize that later. The point of using guides/lines is the important part of this training.
Choosing cool icons for PowerBI Navigation
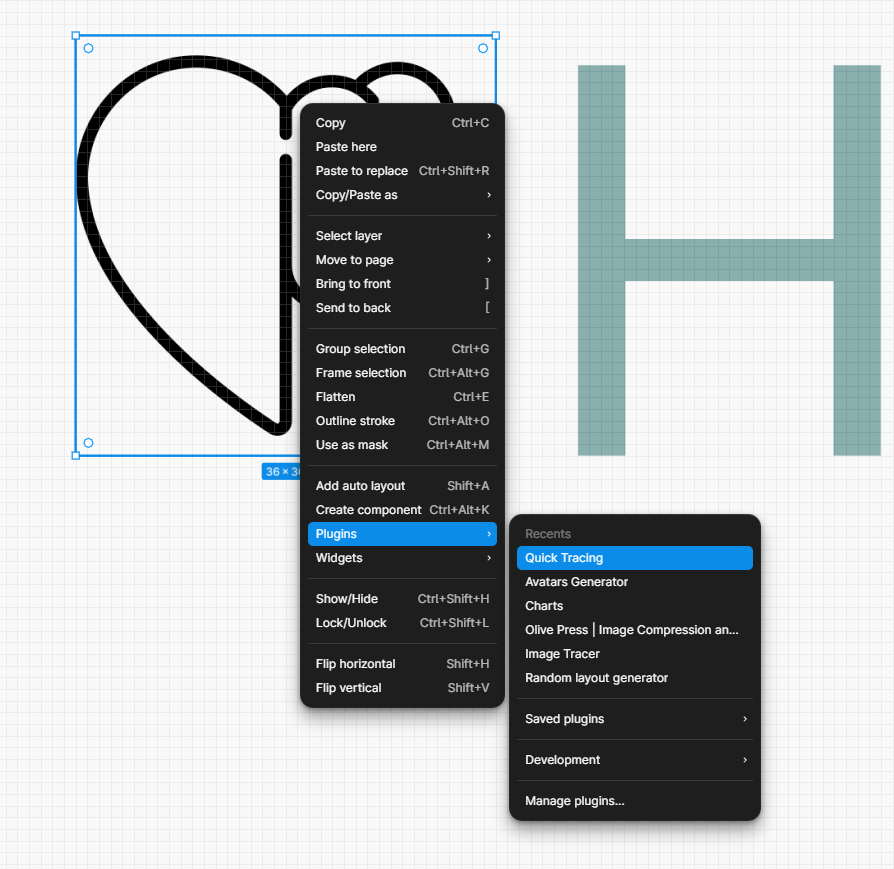
Since we are prototyping and not rushing to production, we need a simply PNG file for icons. Google search will bring up a lot of options you can trace, “black icon mental health heart.”
Simply click a square in figma, and ctrl+v paste.
This is why we created that square in tracing section, it outlines my sizing requirements.
Now, we have two buttons, logo. Things are cooking. Plus, custom icons. Always tell people it’s easy to change icons, this is just a prototype.
Many tracing apps can be found in the figma community. Great for icon tracing. This creates a vector trace of the heart/brain icon.
Once you trace the svg, you can color the file and it’s a vector rendering. I like changing the color to match the pallete.
Now, to finalize the visual. I use more guides but in the shape of a square this time. Find what works best for you.
Insert image into PowerBI
Woot, you’re here! You’re doing you’re own design based on a tracing.
I hope you’re proud of your drawing. If not, simply grab more ideas and trace until you’re satisfied.
Open Insert Tab, then click image. Navigate to the image you created in Figma. Group it and export it.
Start to play with dashboard sizing based on your image size.
Adding your first charts on new style in PowerBI
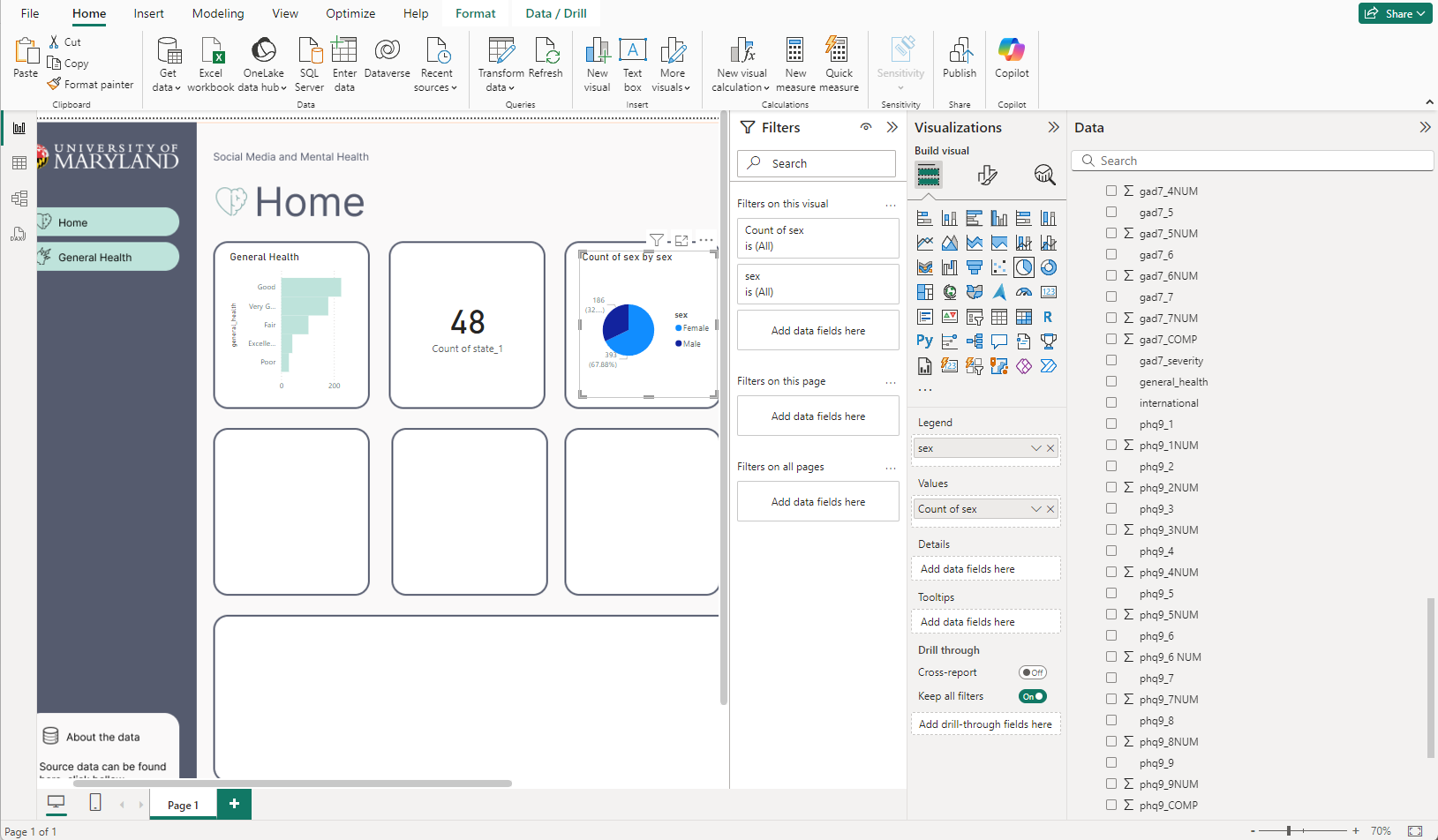
Okay, so you’re adding your new traced design to PowerBI as an image. You fixed the canvas.
And you’re beginning to add charts.
I’ve started with the easier charts, that feel very global. Like the amounts of states accounted for in the overall survey. The differences between gender, and the general health column popped to mind considering our button says General Health too. Even though it’s a place holder, perhaps we can go into detail about general health as a button too. Also, I like making actionable KPI to flow with buttons, so end users know if they click that bar chart, perhaps they will learn more about General health, and also the button General health will take them there too.
Scaling up on your new Traced PowerBI Design Template
Okay, people are going to ask you to change your PowerBI Design, for example pixels aren’t perfect, maybe 2 pixel boarder around charts isn’t great.
This is why I love having my dashboard design in Figma. Easy to edit. Copy and paste and start new styles.
In powerbi, similar process, right click dashboard tab, and click duplicate to duplicate your dashboard.
Now, delete the background image, and add a new image. Should look like this if you’re still adding charts. As long as you don’t move boxes, you’re safe to simply add back the new image and it will fit perfectly.
This is a good sign, you’re not depending on a reporting platform to manage your design elements. You can slap this background into any reporting software.
Now, you have a duplicate tab in PowerBI, I went with nuerophism, a cool design technique that makes it feel like it’s popping off the screen because of the light and dark shadows. Do you notice the differences in the shadows?
Conclusion to Tracing designs with with Figma for PowerBI Desktop
While working with designers, often we are given screenshots of artwork, and tracing allows us to gain what we need to be successful.
I hope you enjoyed this tutorial on creating quick PowerBI products using Figma to trace.
Keep perfecting your craft and let us know if you need help with any dashboard designing services!
We will add more training like this in our articles here on dev3lop, stay tuned.
Although, we started as a Tableau Consulting Company, we have been navigating into more and more PowerBI the past few years.
Recently we had a client reach out and was unsure if their software was Java or JavaScript. We have all been here at least once in our career. Unsure about two buzzwords that sound similar. This lead us to thinking there’s likely a lot of lesser-known facts about JavaScript, like Java is not JavaScript!
Focused on some of the technical aspects that may improve a dev3lopers day.
Here’s a list of 15 examples of 15 lesser-known facts about JavaScript
JavaScript Is Not Java: Despite their names, Java and JavaScript are unrelated. JavaScript was initially named Mocha and later renamed to LiveScript before Netscape’s marketing team settled on JavaScript to capitalize on Java’s popularity.
First-Class Functions: Functions in JavaScript are first-class citizens, meaning they can be assigned to variables, passed as arguments, and returned from other functions.
Closures: JavaScript functions form closures, which means they have access to variables from their outer (enclosing) functions even after the outer function has returned.
Dynamic Typing: JavaScript is dynamically typed, meaning the same variable can hold different types of values at different times. This flexibility can lead to unexpected behavior if not carefully managed.
Prototype-Based Inheritance: Unlike many object-oriented languages, JavaScript uses prototype-based inheritance, allowing objects to inherit properties and methods from other objects.
NaN Is a Number: The typeof NaN is number, which can be counterintuitive. NaN stands for “Not-a-Number,” yet it’s considered a number type.
Double Equals (==) vs. Triple Equals (===): The == operator performs type coercion, converting operands to the same type before comparison. The === operator is stricter and checks both type and value.
Falsy and Truthy Values: JavaScript has several falsy values (false, 0, '', null, undefined, NaN) that evaluate to false in a boolean context. Everything else is truthy.
Hoisting: JavaScript’s default behavior is to hoist variable and function declarations to the top of their containing scope. However, only the declarations are hoisted; initializations remain in place.
Single-Threaded but Asynchronous: JavaScript runs on a single thread (the event loop) but can handle asynchronous operations like I/O events, thanks to its non-blocking nature and features like Promises and async/await.
IIFE (Immediately Invoked Function Expressions): JavaScript supports defining and invoking functions immediately, allowing developers to create a private scope. Example: (function() { console.log('This runs immediately!'); })();
Global Object: In a browser environment, the global object is window, while in Node.js, it’s global. Variables declared with var are attached to the global object, unlike those declared with let or const.
this Keyword: The value of this depends on how a function is called. In the global context, this refers to the global object (window), but inside an object method, it refers to that object.
Arrow Functions and this: Arrow functions don’t have their own this context; instead, they lexically inherit this from their parent scope. This makes them handy for use in callbacks to preserve context.
null vs. undefined: null is an intentional absence of any value and can be set by the programmer, while undefined means a variable has been declared but not assigned a value yet.
These insights reveal some of JavaScript’s quirks and unique characteristics that make it both powerful and sometimes puzzling!
You know, with everyone saying “big data this” and “big data that,” I’m starting to wonder if we have any idea of what big data is all about. From our experience, we see big and small data daily, and how we manage them is typically very similar. Let’s make this fit since we love node.js for any data size.
This comprehensive overview will highlight nodejs data pipelines, and explain why people are moving this direction.
Businesses need to process and analyze vast amounts of data efficiently. Nodejs is just the right tool; combined with Express and Knex, you have yourself a powerful data engineering stack of tools.
What is a data pipeline? Data pipelines are essential for seamless data flow from one system to another, enabling real-time analytics, data warehousing, and machine learning. We use data pipeline as a buzzword that explains how we may be processing data in a full stack. It’s easier than saying processing, fetching, and other terms in the engineering realm.
With its non-blocking I/O and event-driven architecture, Node is an excellent choice for building efficient and scalable data pipelines. We regularly re-use our internal data engineering nodejs product for data warehousing engagements because it allows us to continually advance our data product offering in the competitive advanced analytics consulting world. This guide explores how Node.js can be leveraged to streamline data pipelines, offering practical insights and examples.
Why Choose Node.js for Data Pipelines?
We choose nodejs for data pipelines because it’s efficient, fast, easy to scale, and easy to grow. It’s also within the javascript language, which means it’s extendable. If you haven’t already clearly stated why Nodejs is essential to your ecosystem, it’s good to begin. If you need some help, we have listed a few reasons below.
Node.js uses an asynchronous, non-blocking I/O model, which means it can handle multiple operations simultaneously without waiting for any single one to complete. This is particularly advantageous for data pipelines, where I/O operations, such as reading from a database or writing to a file, are common. Non-blocking I/O ensures the data pipeline remains responsive and can handle high throughput with minimal latency.
Event-Driven Architecture
Node.js operates on an event-driven architecture, making it well-suited for handling real-time data streams. Events trigger specific actions, allowing the system to process data as it arrives. This model is ideal for data pipelines that require real-time processing, such as log aggregation, monitoring, and analytics.
Single Language Across the Stack
Using JavaScript both on the client and server sides simplifies the development process and enhances productivity. Developers can share code between the front and back end, reducing redundancy and maintenance efforts.
Building Blocks of a Node.js Data Pipeline
1. Data Ingestion
Data ingestion is the first step in a data pipeline, involving collecting raw data from various sources. In Node.js, you can use libraries like Axios for HTTP requests or node-fetch to gather data from APIs and fs For reading data from files.
Once data is ingested, it must be processed, including transformations, filtering, and aggregations. Node.js streams are a powerful feature for handling large datasets efficiently.
An example of subtle chunking, a process often used to lower the stress on databases and offers an easy scale-up per pipeline:
Processed data must often be stored in a database or a data warehouse. Node.js supports various databases, including MongoDB, PostgreSQL (our preference, with KNEX), and Redis. Libraries like Mongoose for MongoDB and pg for PostgreSQL make it straightforward to interact with databases.
Tools like Grafana can be integrated to monitor and visualize the data pipeline in real-time. Node.js can send data to monitoring tools directly via APIs or client libraries.
Node.js runs on a single thread, but you can leverage clustering to exploit multi-core systems. The cluster The module allows you to create child processes with the same server port.
Message queues like RabbitMQ or Apache Kafka can be used to decouple and scale different stages of the pipeline. Node.js libraries, such as amqplib for RabbitMQ and kafkajs For Kafka provides easy integration.
Conclusion regarding Streamlining Data Pipelines with Nodejs
With its non-blocking I/O and event-driven architecture, the fact that so many people are using Node, plus Node.js, is a powerful tool for building efficient and scalable data pipelines. Its ecosystem of libraries and frameworks, coupled with its ability to handle real-time data processing, makes it an ideal choice for modern data workflows. By leveraging Node.js for data ingestion, processing, storage, and visualization, developers can create robust and high-performance data pipelines that meet the demands of today’s data-driven world.
If you haven’t heard, real-time data processing has become crucial for applications, but many people don’t understand how it’s handled. In this blog, we break it down, show some code, and explain it easily enough for executives to understand.
So, if you’re ready to invest in streaming technologies, immediate action will be required on your and your company’s behalf. If you’ve never worked in an organization with streaming technology, you may not even know the value at the end of this rabbit hole.
A culture shift is required from:
“we put data into a spreadsheet monthly or quarterly” TO the data is already there and “we don’t have to do anything manually.”
This can often be a shock for people who are constantly updating these files, “wait, now I can focus on my job again?”
In today’s static Excel age, we still feel the pain of not shifting to emerging technologies sooner, and because they are challenging, it’s easy to remove them from the culture or mindset.
Whether it’s monitoring social media trends, processing financial transactions, or managing sensor data from smart devices, the ability to handle data as it arrives is vital. Node.js, with its event-driven, non-blocking architecture, is exceptionally well-suited for real-time data processing. This article delves into the techniques and best practices for leveraging Node.js for real-time data processing.
Why Node.js for Real-time Data Processing?
Helicopter view: Node.js is a top-notch choice for real-time data processing, thanks to its event-driven, non-blocking I/O model. This design lets it handle multiple tasks simultaneously with impressive efficiency, making it perfect for applications that need instant data processing and quick responses. Beyond that, Node.js scales effortlessly, managing numerous simultaneous connections without breaking a sweat. Its rich ecosystem, featuring libraries like Socket.IO for real-time communication and Stream for data handling, makes developing real-time applications a breeze. These combined features make Node.js a powerhouse for building responsive, high-performance, real-time data pipelines.
Event-driven and Non-Blocking I/O
Node.js’s event-driven and non-blocking I/O model enables it to handle multiple operations concurrently. This makes it ideal for real-time applications where data must be processed as soon as it is received without waiting for previous operations to complete.
Scalability
Node.js can handle many concurrent connections with minimal overhead, making it scalable for real-time applications. Its single-threaded nature and clustering allow it to utilize multi-core systems efficiently.
Rich Ecosystem
Node.js boasts a rich ecosystem of libraries and frameworks, such as Socket.IO for real-time communications and Stream for handling streaming data, simplifying the development of real-time data processing applications.
Techniques for Real-time Data Processing
Node.js offers several effective techniques for real-time data processing. WebSockets with Socket.IO enable instant, two-way communication between clients and servers. Streams handle large datasets efficiently by processing data in chunks, avoiding memory overload. Message queues like RabbitMQ help manage and distribute data smoothly. For real-time analytics, integrating with platforms like Apache Kafka ensures robust data handling and insights. These techniques leverage Node.js’s strengths to build powerful and efficient real-time data processing applications.
1. WebSockets with Socket.IO
WebSockets provide a full-duplex communication channel over a single TCP connection, enabling real-time interaction between clients and servers. Socket.IO is a popular library for WebSocket communication in Node.js.
Example:
const http = require('http');
const socketIo = require('socket.io');
const server = http.createServer();
const io = socketIo(server);
io.on('connection', (socket) => {
console.log('New client connected');
socket.on('message', (data) => {
console.log('Message received:', data);
// Process data here
});
socket.on('disconnect', () => {
console.log('Client disconnected');
});
});
server.listen(3000, () => {
console.log('Server is listening on port 3000');
});
2. Streams for Data Processing
Node.js streams are an excellent way to handle real-time data processing. Streams allow you to process data piece by piece without loading the entire dataset into memory.
Message queues help decouple different parts of your application and manage the data flow. RabbitMQ is a robust message broker that can be easily integrated with Node.js using the amqplib library.
Apache Kafka is a distributed streaming platform that can handle real-time data feeds. Node.js can interact with Kafka using the kafkajs library. Kafka is a big beast that we can’t explain in this blog, but it’s cool to see that it works with Kafka in some boilerplate code.
Best Practices for Real-time Data Processing with Node.js
Follow a few best practices to get the most out of real-time data processing with Node.js.
Efficient memory management is crucial—use streams to handle large datasets and avoid memory leaks. Implement robust error handling and logging to ensure reliability and quick issue resolution. Utilize clustering to scale across multiple CPU cores and balance the load effectively. Prioritize security by using HTTPS, validating inputs, and implementing proper authentication.
Lastly, monitor performance with tools like Grafana and Prometheus to keep your system running smoothly and efficiently.
Efficient Memory Management
Real-time applications can quickly become memory-intensive. Use streams to handle large datasets efficiently and avoid loading entire data sets into memory. Monitor memory usage and use tools like heapdump to analyze memory leaks.
Error Handling
Implement robust error handling to ensure your application can recover gracefully from unexpected issues. Use try-catch blocks, handle rejected promises and set up proper logging to capture and analyze errors.
Clustering and Load Balancing
Utilize the cluster module to take advantage of multi-core processors. Implement load balancing to distribute the workload evenly across multiple application instances.
Ensure your real-time data pipeline is secure. Use HTTPS for data transmission, validate and sanitize all inputs to prevent injection attacks, and implement authentication and authorization mechanisms.
Monitoring and Logging
Set up monitoring and logging to track the performance and health of your real-time data pipeline. Tools like Grafana, Prometheus, and ELK Stack (Elasticsearch, Logstash, Kibana) can provide valuable insights into your application’s behavior.
Conclusion regarding Real-time Data Processing with Node.js: Techniques and Best Practices
We love node.js and use it in all of our data engineering consulting engagements because we enjoy using this tool to create data lakes. Whether it’s pulling from an API or database, nodejs has packages available to use. Best practices and techniques are best created internally and spread through each solution. However, we wanted to show some code and discuss some high-level observations from practical experiences.
Node.js, with its non-blocking I/O and event-driven architecture, provides an excellent platform for real-time data processing. By leveraging techniques such as WebSockets, streams, message queues, and real-time analytics platforms, you can build efficient and scalable real-time applications. Adhering to best practices like efficient memory management, robust error handling, and security measures will ensure your data pipeline remains reliable and performant. With the right approach, Node.js can empower your applications to process data in real-time, delivering immediate insights and actions.
Right now, businesses need a way to store, manage, and analyze vast or even small amounts of information, thus the birth of spreadsheets. Companies in the past have relied on businesses like dev3lop.com’s data engineering services to help alleviate the struggle of updating data in a timely fashion, regardless of whether it is ETL or ELT, or both at the same time. We have experience helping companies drag, drop, and write code from the ground floor.
Many companies use expensive drag-and-drop software to manage data because it is easy to use and has a nice visual interface. However, businesses increasingly recognize the benefits of using open-source platforms like Node.js to move, transform, and load data. Node.js is better than expensive ETL products because it can do the same job for free at scale. This shift can save money and make your system more flexible and scalable.
Most cloud offerings will allow you to run nodejs in a free tier for a lifetime due to the amount offered and needed in an environment.
The High Cost of Proprietary Data Warehousing.
Proprietary drag-and-drop data warehousing tools come with significant costs, and even though you may not be using the robust features it’s added each year, you’re paying for it and still paying more each year.
These include:
High Licensing Fees: Commercial software solutions require substantial upfront investments and ongoing licensing fees.
Maintenance Costs: Regular updates, patches, and customer support often incur additional costs.
Limited Customization: While drag-and-drop interfaces are user-friendly, they can limit the ability to tailor solutions to specific business needs.
Why Node.js is a Game-Changer
Node.js, an open-source JavaScript runtime built on Chrome’s V8 JavaScript engine, offers a powerful alternative to traditional data warehousing solutions. Here’s why transitioning to Node.js can be a strategic move:
1. Cost Efficiency
Node.js is open-source, meaning it’s free to use. This immediately eliminates the hefty licensing fees associated with proprietary software. Additionally, a large and active community of developers continually enhances and supports Node.js, ensuring ongoing improvements without extra costs.
2. Scalability
Node.js is designed for scalability. Its non-blocking, event-driven architecture allows it to handle numerous simultaneous connections efficiently, making it ideal for real-time applications and data-intensive processes. This is particularly beneficial for businesses experiencing rapid growth and increasing data volumes.
3. Flexibility and Customization
Unlike rigid drag-and-drop solutions, Node.js offers unparalleled flexibility. Developers can build custom data processing pipelines and integrate seamlessly with other systems and APIs. This customization ensures that the data warehousing solution can evolve with the business’s needs.
4. Performance
Node.js is known for its high performance. Its asynchronous nature allows for faster code execution and data processing and retrieval. This results in more responsive applications and quicker insights from data analysis.
5. Community and Ecosystem
The Node.js ecosystem is rich with modules and libraries that can be easily integrated to extend functionality. From data visualization to machine learning, there’s likely a Node.js module that fits your needs. The active community also means finding support, tutorials, and best practices is straightforward.
Making the Transition: Best Practices
Transitioning from a proprietary data warehousing solution to Node.js requires careful planning and execution. Here are some best practices to ensure a smooth migration:
I’ve come to conclusion this route isn’t for everyone and some companies want to spend millions or as low as $15k annual on a desktop license that will enable someone or many people ad-hoc analytics capabilities but if you multiple that in ten years, you may start regretting, this is where companies like Dev3lop can save you money, so why wait!
Tyler Garrett, Founder
1. Assess Current Infrastructure
Evaluate Existing Setup: Begin by thoroughly examining your current data warehousing environment. Document all components, including hardware, software, data pipelines, storage solutions, and integrations.
Identify Components for Replacement or Upgrade: Determine which parts of your system are outdated, inefficient, or incompatible with Node.js. Identify dependencies and assess potential risks associated with changes.
Create a Detailed Transition Plan: Develop a comprehensive plan outlining the steps needed to transition to Node.js. This should include timelines, resource allocation, risk mitigation strategies, and fallback plans. Prioritize critical components to ensure business continuity.
2. Skill Development
Invest in Training: Allocate resources for training your team in Node.js. This could include formal courses, online tutorials, or workshops. Ensuring that your developers are proficient in JavaScript and familiar with Node.js’s event-driven architecture is crucial.
Encourage Certification and Continuous Learning: Encourage team members to pursue certifications and participate in continuous learning opportunities. Staying updated with the latest trends and best practices in Node.js will maximize your team’s effectiveness.
Build a Knowledge Base: Create a repository of internal documentation, best practices, and code snippets to facilitate knowledge sharing within the team. This will help new members get up to speed quickly and ensure consistency in development practices.
3. Pilot Projects
Start Small: Select a few non-critical projects to implement using Node.js. These pilot projects should be manageable in scope but comprehensive enough to provide meaningful insights into Node.js’s capabilities.
Evaluate Performance and Feasibility: Monitor Node.js’s performance in these pilot projects. Evaluate aspects such as speed, scalability, ease of integration, and any challenges encountered.
Adjust Based on Feedback: Use feedback from the pilot projects to refine your approach. Address any issues and make necessary adjustments before expanding the use of Node.js to more critical components of your data warehousing system.
4. Incremental Migration
Plan for Phased Implementation: Break down the migration process into manageable phases. Begin with less critical components to minimize risk and gain confidence.
Ensure Integration Continuity: Gradually transition services to Node.js while seamlessly integrating existing systems. This approach helps identify and mitigate integration issues early.
Monitor and Optimize: Continuously monitor the performance and stability of the migrated components. Optimize configurations and processes as needed to ensure that the new system meets or exceeds the performance of the old one.
5. Leverage Community Resources
Engage with the Node.js Community: Participate in online forums, discussion groups, and community events. Community engagement can provide valuable insights, support, and best practices.
Utilize Open-Source Libraries: Take advantage of the vast array of open-source libraries and modules available for Node.js. These can significantly speed up development and reduce costs.
Stay Updated with Best Practices: Regularly follow Node.js blogs, newsletters, and official documentation to stay informed about the latest updates and best practices. This ensures that your team remains at the forefront of Node.js development techniques.
By following these expanded steps, businesses can ensure a smooth and effective transition from traditional data warehousing solutions to a modern, open-source Node.js environment.
Conclusion on Drag-n-drop or Node
Transitioning from expensive drag-and-drop data warehousing solutions to Node.js is a cost-saving measure and a strategic decision offering enhanced flexibility, scalability, and performance. We have over a decade of experience helping companies transition to code solutions and drag-n-drop ETL solutions, and now that we are on the nodejs journey, we are eager to keep taking our clients along the path if that’s in their vision!
As businesses continue to seek ways to optimize their operations and reduce costs, embracing open-source solutions like Node.js will become increasingly appealing.
By carefully planning the transition and leveraging Node.js’s robust capabilities, organizations can unlock new levels of efficiency and innovation in their data management processes. Now is the time to explore the possibilities and shift towards a more agile and cost-effective data warehousing solution.